

前言
在深度学习项目中,将数据集划分为训练集和验证集是非常重要的一步。本文将介绍如何使用 Python 脚本将通过 LabelImg 标注的图片和对应的标签文件分为训练集、验证集和测试集,并提供详细的步骤和示例代码。
1. 项目背景
在使用 YOLO 等深度学习模型进行图像识别时,训练集和验证集的划分是确保模型性能的重要步骤。本文提供一个自动化的 Python 脚本,帮助用户将标注的数据集按照指定比例划分为训练集和验证集。代码将会读取指定的图片和标签文件目录,随机打乱数据顺序,然后将数据分配到对应的文件夹中。
2. 准备工作
在开始之前,请确保你已经安装了 Python 环境,并将待处理的图片和标签文件放在指定目录下。
- 图片目录:
C:\Users\Administrator\Desktop\allData\images
如图:图片文件都被放置于allData目录下的images中

- 标签目录:
C:\Users\Administrator\Desktop\allData\labels
如图:图片所对应的标签文件都放置于allData目录下的labels中
- 期望的输出目录:
C:\Users\Administrator\Desktop\SplitData
3. 代码实现
以下是将数据集划分为训练集和验证集的 Python 代码:
因为我这里不需要测试test集,就将test的占比设为了0
import os
import shutil
import random
# 设置随机种子
random.seed(0)
def split_data(file_path, xml_path, new_file_path, train_rate, val_rate, test_rate):
'''====1.将数据集打乱===='''
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
# 将两个文件通过zip()函数绑定
data = list(zip(each_class_image, each_class_label))
# 计算总长度
total = len(each_class_image)
# random.shuffle()函数打乱顺序
random.shuffle(data)
# 再将两个列表解绑
each_class_image, each_class_label = zip(*data)
'''====2.分别获取train、val、test这三个文件夹对应的图片和标签===='''
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
'''====3.设置相应的路径保存格式,将图片和标签对应保存下来===='''
# train
for image in train_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# val
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
# test
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
os.makedirs(new_path1, exist_ok=True)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = r"C:\Users\Administrator\Desktop\allData\images" # 原图片路径
txt_path = r"C:\Users\Administrator\Desktop\allData\labels" # 原标签路径
new_file_path = r"C:\Users\Administrator\Desktop\SplitData" # 划分后存放目录
# 设置划分比例
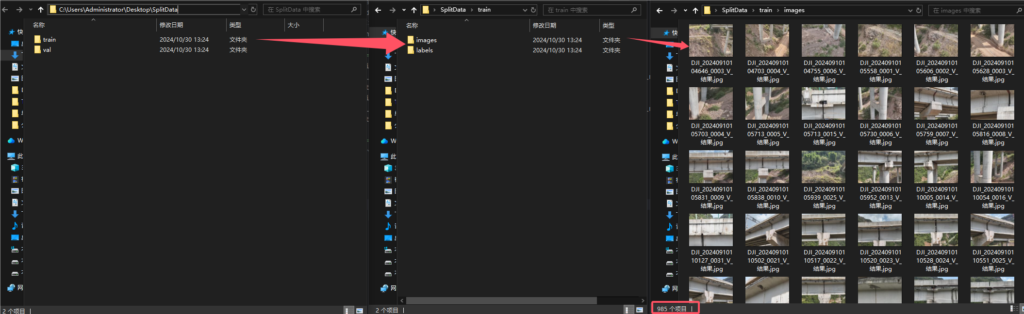
split_data(file_path, txt_path, new_file_path, train_rate=0.85, val_rate=0.15, test_rate=0)4.运行结果
运行后,可以看到数据集已经按照代码中 train:val=0.85:0.15的比例划分了
以上是将标注数据集划分为训练集和验证集的解决方案,欢迎在幽络源网站上获取更多源码和技术教程!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END






暂无评论内容