

场景
在使用 YOLOv8 训练目标检测模型时,标注数据往往需要一致的类别标签配置文件 (classes.txt) 和标注文件格式。当多个标注人员各自进行标注而没有统一类别标签时,会导致不同的标签顺序和编号,造成训练时类别错乱。本文将展示如何利用 Python 自动化处理这种数据不一致问题,生成一个统一的 classes.txt,确保模型训练数据一致性。这是幽络源【浏览器搜索幽络源,分享原创教程】为大家准备的 Python 实用教程。
问题描述
在数据标注阶段,多个标注员各自对图片进行标注,但每个标注员的 classes.txt 文件内容不同。
如下所示:
-
标注员A的
classes.txt包含以下类别:

-
标注员B的
classes.txt内容为:

由于标签不一致,直接将数据合并会导致类别编号不匹配,影响模型的训练。为此,我们通过 Python 编写自动化脚本,将各标注员的标签文件合并,并按统一标准更新所有标注文件。
解决方案步骤
以下是详细的步骤说明:
最后会给出一个完整的代码
步骤 1:合并所有标注员的 classes.txt
首先,我们需要收集所有标注人员的 classes.txt 文件,生成一个统一的标签列表 merged_classes.txt。该列表将包含所有类别标签,并按照字母顺序排列,确保编号统一。代码如下:
import os
def merge_classes(classes_files):
all_classes = set()
for file in classes_files:
with open(file, 'r', encoding='utf-8') as f:
for line in f:
class_name = line.strip()
if class_name:
all_classes.add(class_name)
return sorted(all_classes)步骤 2:生成类别映射表
在生成了统一的类别列表后,我们需要创建每个标注员标签编号到统一编号的映射表。这个映射表将帮助我们将各个标注文件中的类别编号替换为统一编号,确保一致性。代码如下:
def generate_mappings(classes_files, merged_classes):
mappings = []
for file in classes_files:
mapping = {}
with open(file, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
class_name = line.strip()
if class_name in merged_classes:
mapping[idx] = merged_classes.index(class_name)
mappings.append(mapping)
return mappings步骤 3:更新标注文件中的类别编号
通过映射表,我们可以将每个标注文件的类别编号更新为统一编号。代码如下:
def update_label_file(file_path, mapping):
new_lines = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
class_id = int(parts[0])
new_class_id = mapping.get(class_id)
if new_class_id is not None:
new_line = f"{new_class_id} " + " ".join(parts[1:]) + "\n"
new_lines.append(new_line)
with open(file_path, 'w', encoding='utf-8') as f:
f.writelines(new_lines)步骤 4:批量更新所有标注文件
此步骤通过遍历每个标注员的文件夹,对其中的每个标注文件进行更新操作,以确保所有文件的类别编号统一。同时,通过生成 .mapping_done 文件,避免重复处理文件。代码如下:
def update_folder_labels(folder_path, mapping):
flag_file = os.path.join(folder_path, ".mapping_done")
if os.path.exists(flag_file):
print(f"{folder_path} 已处理过,跳过更新")
return
for file_name in os.listdir(folder_path):
if file_name.endswith('.txt'):
update_label_file(os.path.join(folder_path, file_name), mapping)
with open(flag_file, 'w') as f:
f.write("mapping done")
print(f"{folder_path} 内的标注文件已更新")主函数:执行数据整合
主函数负责调用上述各步骤,对数据进行批量更新。首先定义标注人员的 classes.txt 路径,然后保存合并后的 merged_classes.txt。接下来,针对每个标注文件夹,按步骤生成映射并更新文件。
def main():
classes_files = [
r"path_to_annotator1_classes.txt",
r"path_to_annotator2_classes.txt",
r"path_to_annotator3_classes.txt"
]
merged_classes = merge_classes(classes_files)
with open(r"path_to_save_merged_classes.txt", 'w', encoding='utf-8') as f:
f.write("\n".join(merged_classes))
print("统一的 classes.txt 已生成:", merged_classes)
mappings = generate_mappings(classes_files, merged_classes)
folders = [
r"path_to_annotator1_label_folder",
r"path_to_annotator2_label_folder",
r"path_to_annotator3_label_folder"
]
for folder, mapping in zip(folders, mappings):
update_folder_labels(folder, mapping)
if __name__ == "__main__":
main()完整代码
注意 main函数中的 classes_files 和 folders 一定要对应 ,不然会错乱 ,建议执行代码前先备份图片和标签 ,以便于对比校验
import os
# 1. 收集所有标注人员的 classes.txt,并生成统一的 classes
def merge_classes(classes_files):
all_classes = set()
for file in classes_files:
with open(file, 'r', encoding='utf-8') as f:
for line in f:
class_name = line.strip()
if class_name:
all_classes.add(class_name)
return sorted(all_classes)
# 2. 生成每个标注人员的类别映射表
def generate_mappings(classes_files, merged_classes):
mappings = []
for file in classes_files:
mapping = {}
with open(file, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
class_name = line.strip()
if class_name in merged_classes:
mapping[idx] = merged_classes.index(class_name)
mappings.append(mapping)
return mappings
# 3. 更新单个标注文件的类别编号
def update_label_file(file_path, mapping):
new_lines = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
class_id = int(parts[0])
# 更新类别编号
new_class_id = mapping.get(class_id)
if new_class_id is not None:
new_line = f"{new_class_id} " + " ".join(parts[1:]) + "\n"
new_lines.append(new_line)
with open(file_path, 'w', encoding='utf-8') as f:
f.writelines(new_lines)
# 4. 批量更新指定文件夹内的所有标注文件
def update_folder_labels(folder_path, mapping):
# 检查标志文件
flag_file = os.path.join(folder_path, ".mapping_done")
if os.path.exists(flag_file):
print(f"{folder_path} 已处理过,跳过更新")
return
# 更新标注文件
for file_name in os.listdir(folder_path):
if file_name.endswith('.txt'): # 假设标注文件是 .txt 格式
update_label_file(os.path.join(folder_path, file_name), mapping)
# 创建标志文件
with open(flag_file, 'w') as f:
f.write("mapping done")
print(f"{folder_path} 内的标注文件已更新")
# 主函数
def main():
# 标注人员的 classes.txt 路径
classes_files = [
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\三岔河大桥左幅万巴方向、山岔河大桥右幅巴万方向-杜怡鸿\classes.txt",
# 注人员1的 classes.txt 路径
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\柯家河大桥左幅万巴方向、三角河大桥右幅巴万方向、三角河大桥左幅万巴方向 - 蒋松林\classes.txt",
# 注人员2的 classes.txt 路径
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\陈家河大桥右副巴万方向,柯家河大桥右副巴万方向-申恭伟\classes.txt"
# 注人员3的 classes.txt 路径
]
# 生成合并后的类别列表
merged_classes = merge_classes(classes_files)
# 保存新的 classes.txt
with open(r"D:\A01PythonProjects3123\标注合并\截止10.28merged_classes.txt", 'w', encoding='utf-8') as f:
f.write("\n".join(merged_classes))
print("统一的 classes.txt 已生成:", merged_classes)
# 生成每个标注人员的类别映射表
mappings = generate_mappings(classes_files, merged_classes)
# 更新标注文件夹路径
folders = [
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\三岔河大桥左幅万巴方向、山岔河大桥右幅巴万方向-杜怡鸿\label",
# 注人员1的标注文件夹
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\柯家河大桥左幅万巴方向、三角河大桥右幅巴万方向、三角河大桥左幅万巴方向 - 蒋松林\label",
# 注人员2的标注文件夹
r"D:\A01PythonProjects3123\标注合并\截止10.28\10.17缺陷汇总\陈家河大桥右副巴万方向,柯家河大桥右副巴万方向-申恭伟\label"
# 注人员3的标注文件夹
]
# 执行批量更新
for folder, mapping in zip(folders, mappings):
update_folder_labels(folder, mapping)
if __name__ == "__main__":
main()合并后检验
可以看到合并后classes.txt文件变为了如下

用原来的标签对比现在合并后的标签看是否正确
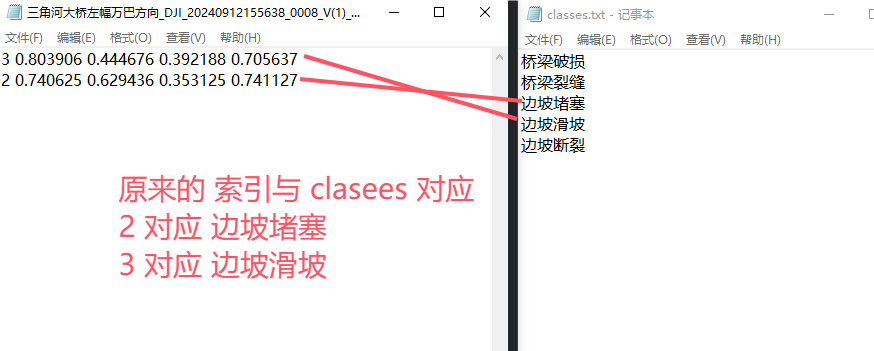
再查看现在更新后的标签与合并后的classes的对应关系是否与原来的对应关系一致
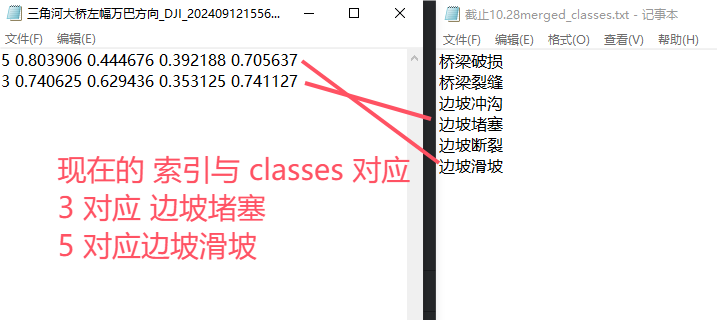
可以看到,合并更新标签后,对应关系是正确的,因此现在可以将所有图片 和 所有标签 分别放入同一个目录,使用合并后的classes.txt进行训练了
总结
通过以上方法,我们实现了自动化合并多个标注员的标签文件,并统一了标注文件的类别编号。这样处理后的数据可以直接用于 YOLOv8 模型训练,避免了因为类别标签不一致带来的问题。幽络源持续分享实用的 Python 工具与技术教程,帮助您更高效地处理数据和训练模型。






暂无评论内容