

教程目的:
yolov8的安装配置到训练模型,并完成使用模型进行识别
前提注意:
yolov8要求Python需要版本必需大于等于3.10,我用的Python3.12.3, 这里分享下Python3.12.3的安装器=>https://pan.quark.cn/s/2f9cad8130ab
以及教程中用到的yolov8源码、权重文件、GPU配套版本的Torch => https://pan.quark.cn/s/388cdfd7ca3f
大致步骤
1.下载源代码并下载所需库
2.更换GPU版本的Torch和Numpy版本
3.下载权重文件
4.准备数据集
5.开始训练
6.测试模型
步骤1:下载源代码并下载所需库
下载yolov8源代码然后Pycharm创建项目,并将源代码放入进行解压


然后下载所需库,控制台执行命令 pip install ultralytics
pip install ultralytics提示:现在官方提供下载所需库的命令是pip install ultralytics,而不再是通过requirements.txt下载库了,并且源码也删除了requirements.txt
步骤2:更换GPU版本的Torch和Numpy版本
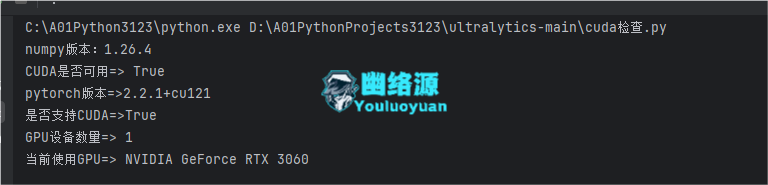
所需库下载完了后,默认下载的torch是CPU版本的,我需要GPU版本的torch,因此还需要更换torch的版本,我们可以先检查下torch的版本以及cuda是否可用,根目录创建一个py文件,名为cuda检查.py,放置如下代码并且执行:
import torch
import numpy as np
# 检查GPU、Cuda
print("numpy版本:"+np.__version__)
print("CUDA是否可用=>", torch.cuda.is_available())
print("pytorch版本=>"+torch.__version__)
print("是否支持CUDA=>"+str(torch.cuda.is_available()))
# 如果有 GPU 可用,打印 GPU 数量和名称
if torch.cuda.is_available():
print("GPU设备数量=>", torch.cuda.device_count())
print("当前使用GPU=>", torch.cuda.get_device_name(torch.cuda.current_device()))
else:
print("没有GPU可用,当前将运行在CPU上")
如果没问题,会显示如下,那么你可以直接去看步骤3了
如果你的pytorch显示cpu版本的,且numpy提示报错了,请继续看如下解决方案:
2.1下载cuda,更换GPU版本的torch
- cuda官方下载链接:https://developer.nvidia.com/cuda-toolkit-archive
- 我下载的是 12.2.0 版本,安装时选择默认路径即可。
然后来到 PyTorch官网 ,因为我下载的是CUDA12.2,官网往下拉可以看到一个注释为CUDA 12.1的,这里可以看到我们应当使用的torch版本,记住这几个版本号

然后来到PyTorch库官方下载页
使用快捷键ctrl+f搜索并下载GPU配套版本torch:
torch:搜索 cu121/torch-2.2.1 (版本小一点是可以的),选择 cp312-win 的版本(因为我是python3.12且为windows)

torchvision:搜索 cu121/torchvision-0.17.1,选择 cp312-win 的版本。

torchaudio:搜索 cu121/torchaudio-2.2.1,选择 cp312-win 的版本。

三个whl文件下载完后建议放到yolov8根目录,然后cmd进入此目录,依次执行以下三条命令安装:
pip install "torch-2.2.1+cu121-cp39-cp39-win_amd64.whl"
pip install "torchvision-0.17.1+cu121-cp39-cp39-win_amd64.whl"
pip install "torchaudio-2.2.1+cu121-cp39-cp39-win_amd64.whl"注意:安装第一个whl文件时会出现红色文字提示,这不是说安装失败,是提示还需要安装torchvision

2.2更换numpy版本
我是遇到这个问题了,yolov8要求numpy版本不得大于2.0,因此我需要先卸载当前大于2.0版本的numpy,然后降低版本为2.0以下,依次执行如下命令:
1.卸载现有的Numpyku
pip uninstall numpy
2.安装2.0以下且yolov8支持的numpy版本
pip install numpy==1.26.4最后建议执行下刚才创建的cuda检查.py文件,看看是否已经完成了GPU版本的torch安装
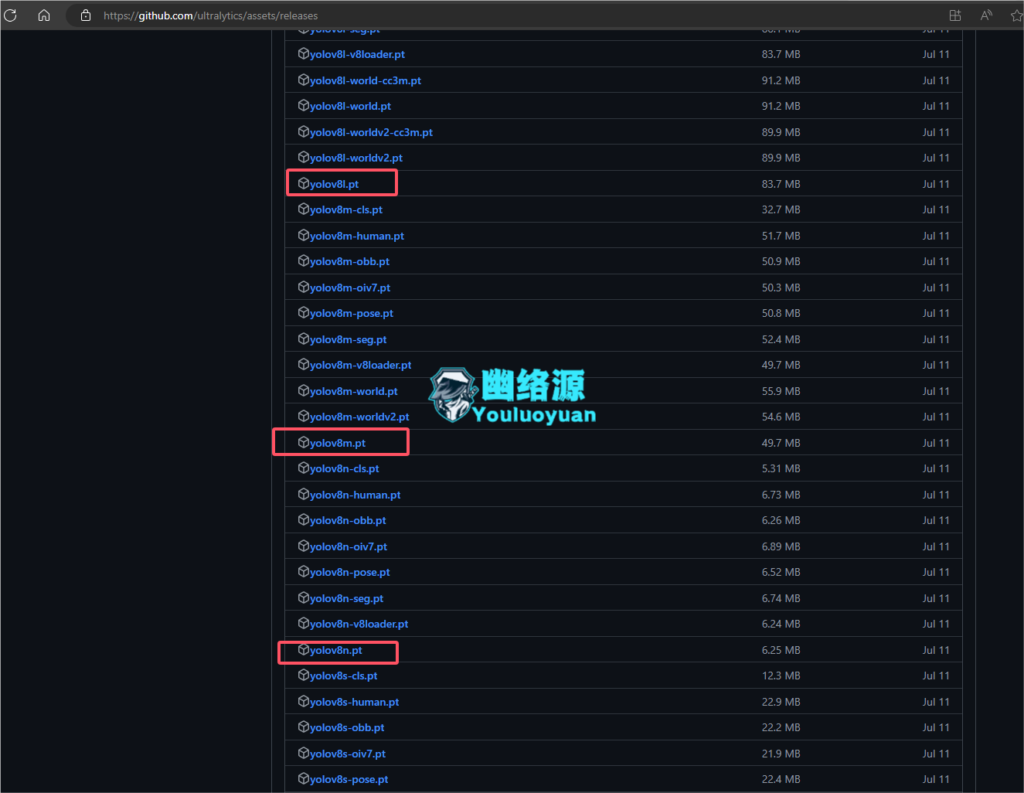
步骤3:下载权重文件
下载权重文件(也成为预训练检查点文件),然后建议放入yolov8源码根目录
官网下载=>https://github.com/ultralytics/assets/releases
我这里下载的是yolov8n.pt
步骤4:准备数据集
关于准备数据集这个东西,完整的方式是先准备图片,再用labelImg去标注图片,这里我提供个标注好的裂缝缺陷数据集,可直接开始训练,见夸克盘内的splitData.zip和CrackConfig.yaml => 标记好的裂缝缺陷数据集(幽络源整理)
如需要学习如何自己制作数据集合,请看这里的教程=> Yolov5图像识别教程包成功-幽络源原创
步骤5:开始训练
为方便理解,在根目录下建立文件夹名为MyTrain,然后将数据集和相关配置放进去,如图

注意:在CrackConfig.yaml中你需要将train和val更改为你自己的绝对路径!!!
然后就是开始训练了,在yolov8源码根目录打开控制条,执行如下命令即可开始训练:
yolo train data="D:\A01PythonProjects3123\ultralytics-main\MyTrain\CrackConfig.yaml" model="D:\A01PythonProjects3123\ultralytics-main\yolov8n.pt" epochs=200 imgsz=640 batch=8 workers=8 device=0参数提示:
- data是数据集配置文件的绝对路径
- model是下载的权重文件的绝对路径,一定要绝对路径
- epochs是训练轮次
- imgsz是指定图片的尺寸
- batch指定每一批处理数量
- workers指定线程工作数量
- device指定使用显卡还是CPU还是其他,为0则表示使用显卡
命令一运行,就可以看到开始训练了,如下2张图:

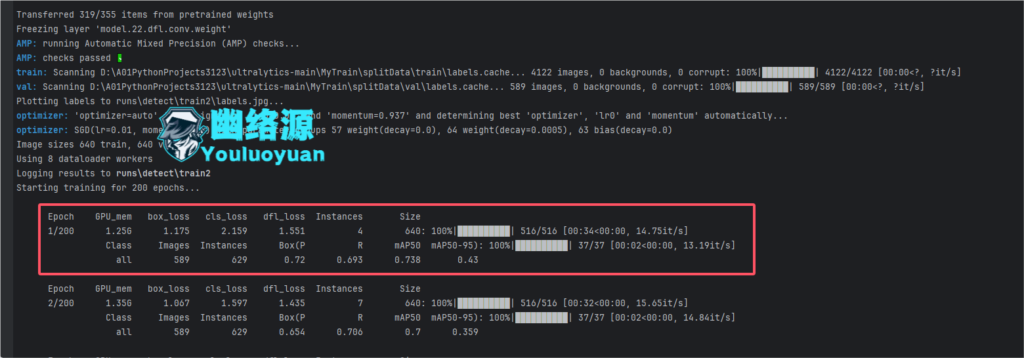
训练完后可以看到结果表示在根目录的runs/detect/train2下,可以看到weights下有个best.pt,这便是我们的最优模型文件,如图
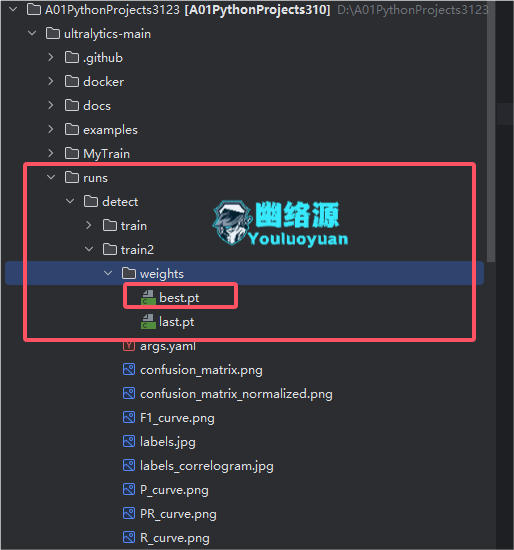
步骤6:测试模型
然后在根目录建立py文件名为Main.py,加入如下代码,然后找一张相关的图进行测试:
注意:将模型文件绝对路径和图片路径替换为你自己的!!!
from ultralytics import YOLO
yolo=YOLO(model=r"D:\A01PythonProjects3123\ultralytics-main\runs\detect\train2\weights\best.pt",task="detect")
results=yolo(source=r"C:\Users\Administrator\Pictures\test.jpg",save=True)然后运行,运行后可以看到控制台提示识别的结果在runs\detect\predict目录下,如图

结语
不得不说yolov8其实还要比yolov5简单的多,幽络源的yolov8搭建使用基础教程结束,如有不懂,可加群询问。







暂无评论内容