

前言
出这个教程的背景需求是:有的项目需要批量导出Word报告,人工写报告太慢了,于是用Python来批量生成报告,但是报告中的某些文字来源于图片中,免费的OCR库识别率很差,无论怎么调整都会有错误的识别,因为图片背景比较复杂,于是用Python整合百度OCR进行图片文字识别,发现非常的好用,而且每月百度OCR都有1千的免费使用次数额度,完全满足普通场景。
步骤概述
1.百度云开启OCR
3.Python整合百度云OCR
4.多场景测试
5.封装为工具函数
步骤1:百度云开启OCR
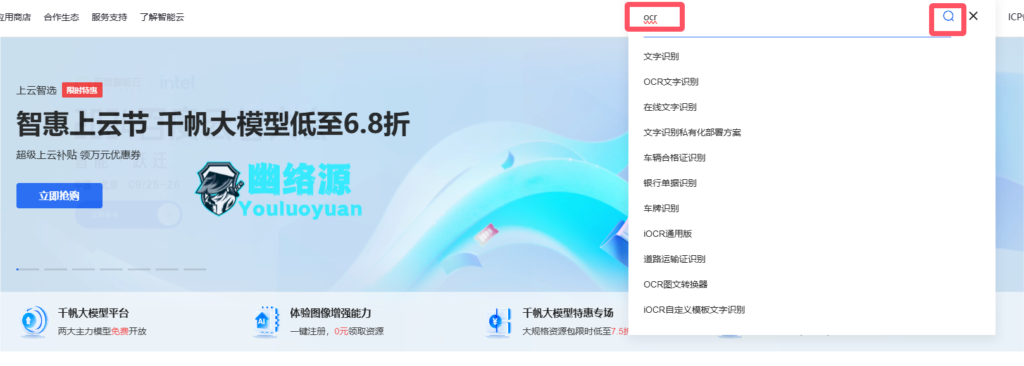
点击立即使用,如图
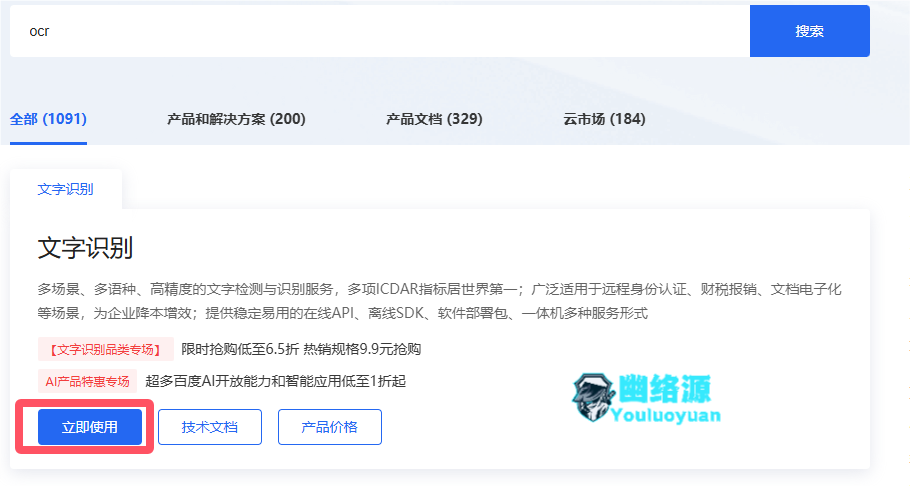
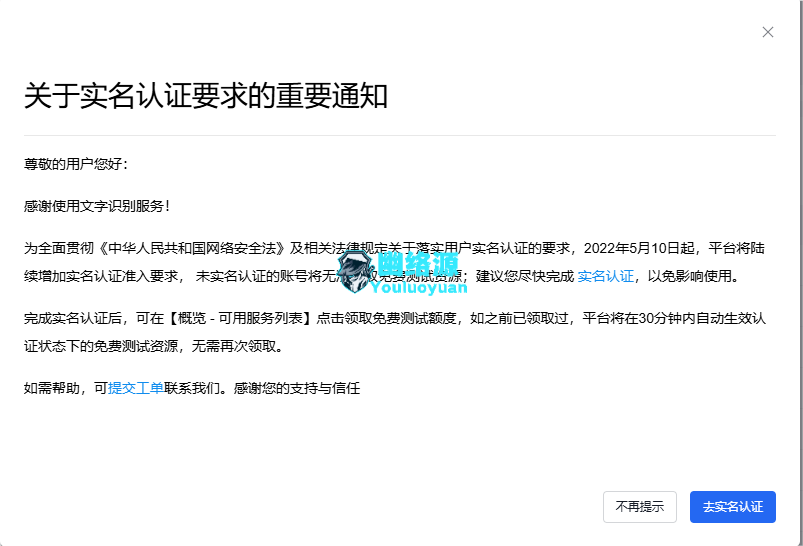
完成实名,如图
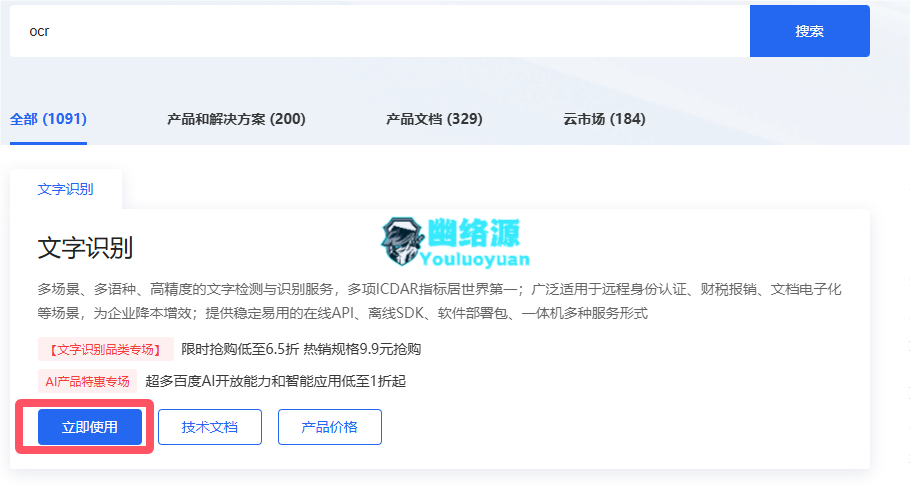
完成实名后还是点击立即使用去控制台,如图
点击概述中的去领取,如图
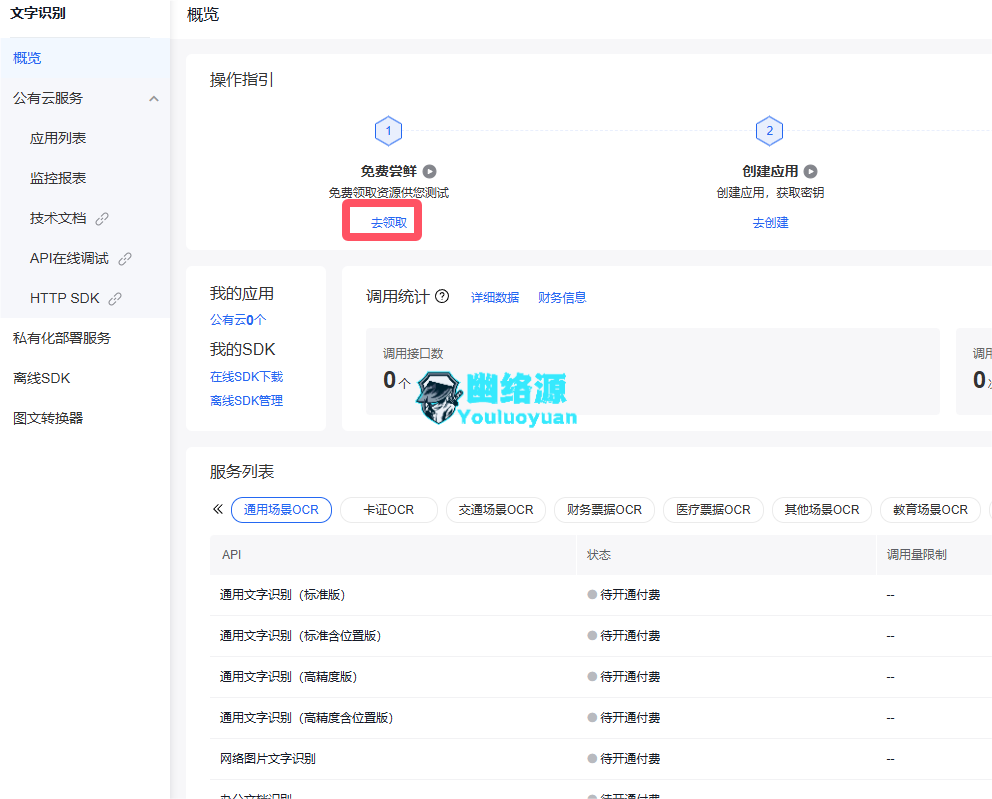
选择通用场景OCR,勾选全部,点击0元领取,如图


步骤2:创建OCR应用并获取密钥
在控制点击创建应用,如图

填入任意名称,只勾选通用文字识别(标准版),底部选择个人,描述填入个人测试,然后点击立即创建,如图
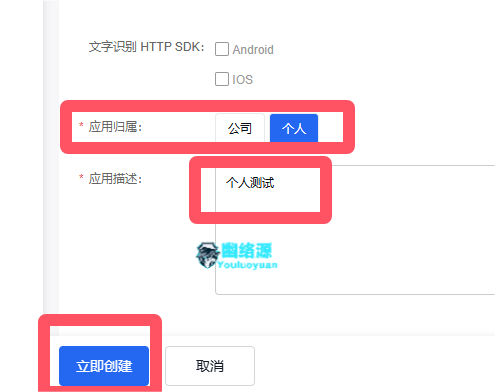
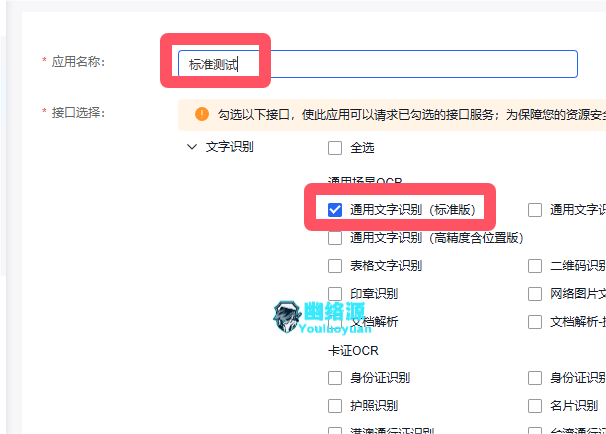
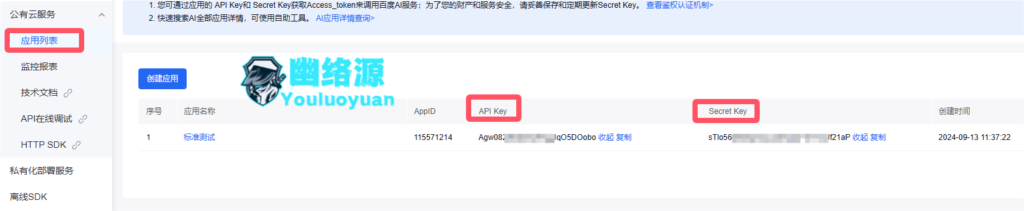
创建后可在控制台的应用列表看到自己的密钥
API Key就是access_key_id,Secret Key就是access_key_secret
步骤3:Python整合百度云OCR
点击左侧栏目的API在线调试,然后切换到通用文字识别(标准版),如图
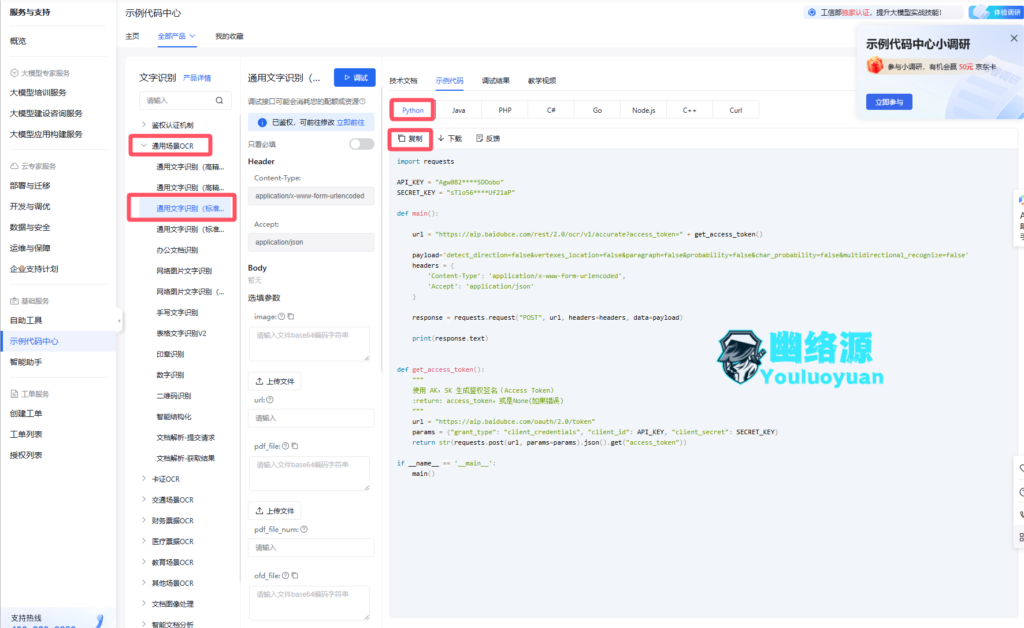
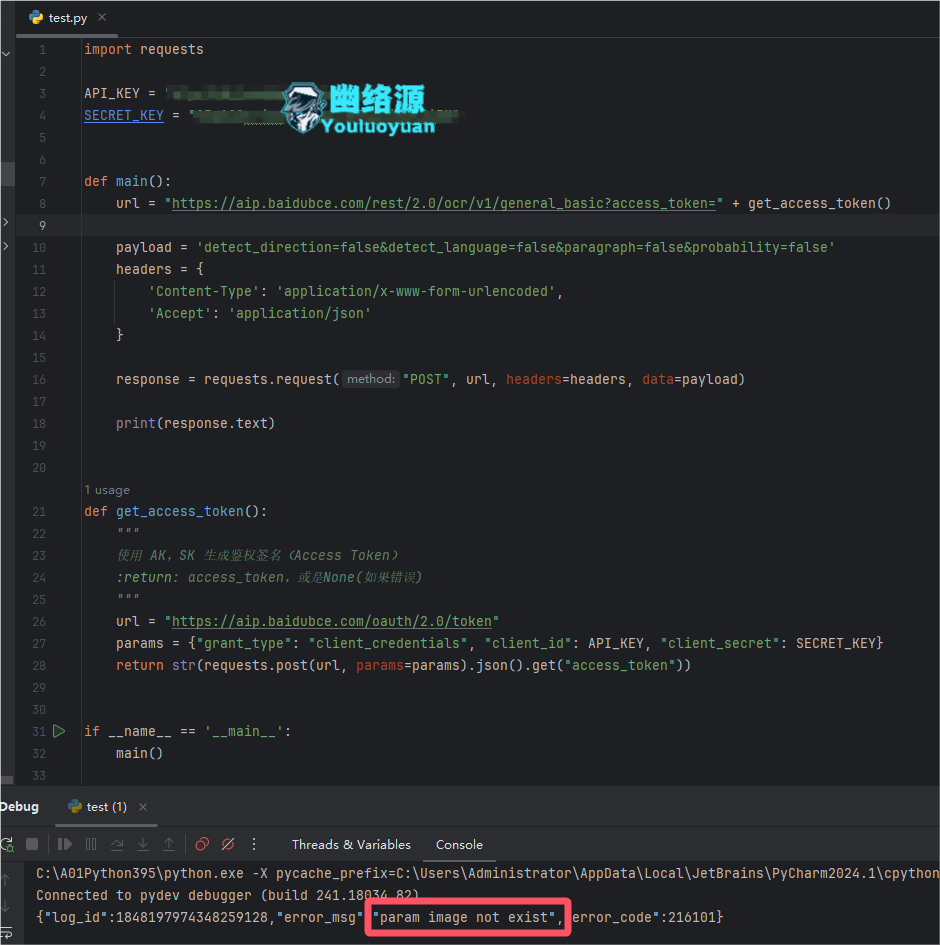
在上图此时可以看到右边直接为我们演示了python的示例代码,我们将其复制下来,在pycharm中进行测试修改,然后直接运行看看,可以看到提示我们参数中没有携带图片,如图
来到刚才的示例代码处,切换到技术文档(注意:还是通用文字识别标准版),往下拉可以看到有个image参数,这个参数就是提供给我们传图片的,如图

来到pycharm,我们创建一个函数名为 get_file_content_as_base64,用于获取读取图片数据,代码为如下
def get_file_content_as_base64(path, urlencoded=False):
"""
获取文件base64编码
:param path: 文件路径
:param urlencoded: 是否对结果进行urlencoded
:return: base64编码信息
"""
with open(path, "rb") as f:
content = base64.b64encode(f.read()).decode("utf8")
if urlencoded:
content = urllib.parse.quote_plus(content)
return content
然后我们找一张带文字的图片放在和python文件同目录下,最好是背景比较复杂的,这样更能体现大厂OCR的强大之处,我使用的图为如下

一定要注意:所使用的图片不可超过8m,因为百度OCR不支持大图的处理,若非要处理,可用其他工具将图片压缩体积
我将图片和python文件放在一起,便于测试,如图
现在我们向代码中传递图片并运行代码,使用刚才创建的函数 get_file_content_as_base64 获取图片数据,然后在payload后拼接图片参数,运行,如图

可以看到控制台中便是OCR识别后响应的JSON数据,至此,幽络源的python整合OCR图像文字识别基础教程结束,后续可根据需要自行封装为工具函数、处理识别后的数据、做成识别软件等。
我们的网络技术交流Q群:307531422







暂无评论内容