

教程目的
将yolo训练好的识别模型与Flask整合为一个WEB接口,供外部调用接口并且并携带图片路径,然后返回图片识别后的相关信息
前提准备
训练好的模型、对应模型的yaml文件、以及yolo相关环境(这里我演示的是4000张裂缝缺陷经过200轮训练的模型)
为方便大家快速学习,这里我免费提供训练好的模型和其相关的配置文件(包含数据集,也可以自己训练) –> https://pan.quark.cn/s/17ed9f416cf2
大致步骤
1.测试模型是否可用
2.删减detect.py中无关的代码
3.修改detect.py使其能够获取到图片识别后的相关信息
4.将detect与flask整合为Web接口
5.模拟请求调用接口
步骤1:测试模型是否可用
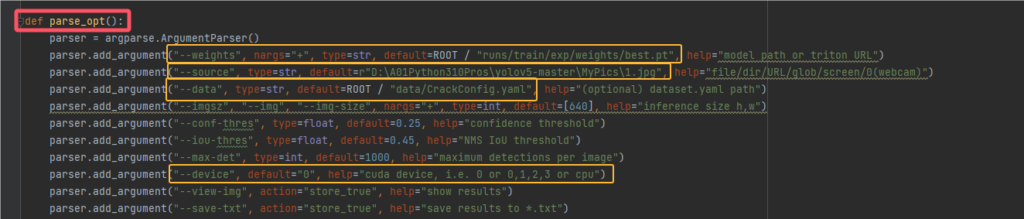
现在我们有模型文件best.pt和其相关的配置文件CrackConfig.yaml,来到detect.py,先将绿色的注释删掉,方便查看,然后定位到parse_opt函数,修改的内容包括如下:
1.weights参数:填写我们的best.pt文件路径,我将其放在yolo根目录的runs/train/exp/weights/best.pt,由于这里的root就是指yolov5本身的根目录,因此只需要填写runs/train/exp/weights/best.pt
2.source参数:现在是测试模型是否可用,去掉root,填写一张裂缝缺陷图片的绝对路径
3.data参数:即填写对应配置文件CrackConfig.yaml
4.device参数:我这里用的显卡去跑,只有一个独立显卡,所以填0
如图是我修改后的参数:
然后运行detect.py文件,yolo就会去识别source下的图片,结果如图:
可以看到控制台提示运行后结果在runs\detect\exp下
补充一句:这里的裂缝识别识别出来三个位置,但明显两边不是裂缝,可以看到两边的小数比中间的0.91小多了,这个是置信度,可以在conf-thres参数调整,默认是0.25,也就是只要识别出来的可信度大于0.25就认为是裂缝,可自行增大调整参数。

步骤2:删减detect.py
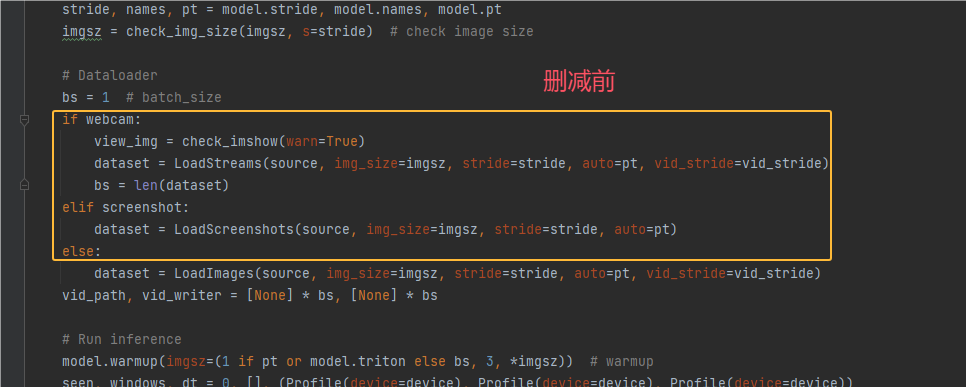
上面已经测试整个程序是可以运行的,现在我们就来删减无关代码
首先我们这里处理的是图片,因此与图片无关的代码我们需要删掉
删减前后对比结果如下2张2:

2.定位到 csv_path = 和 if save_csv:,我这里不需要保存到csv进行数据分析,因此删掉
删减前后对比结果如下4张图



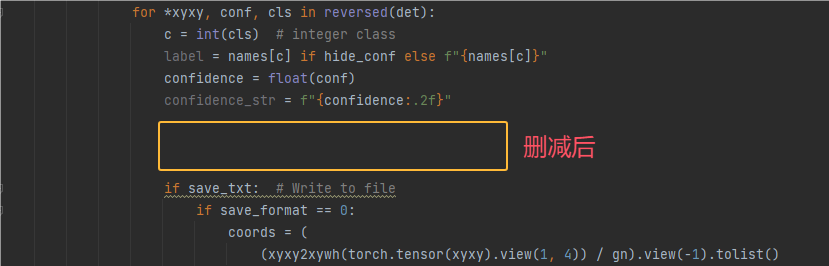
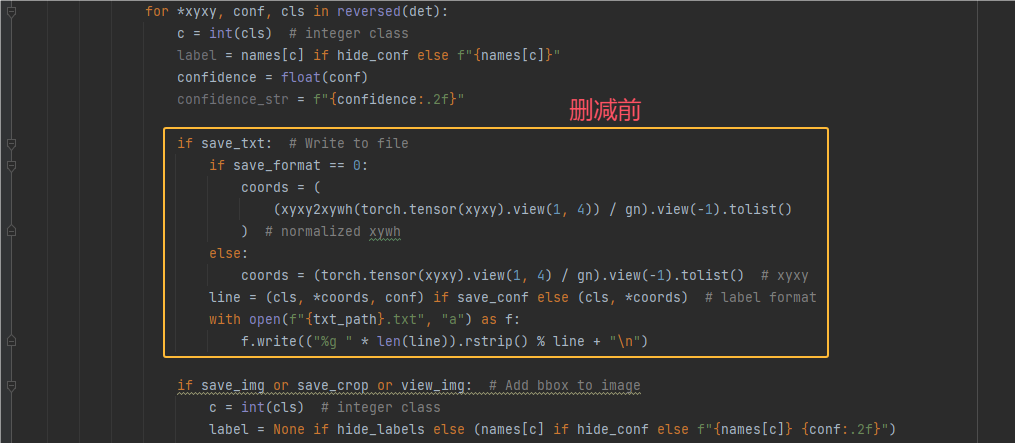
3.定位到 if save_txt: ,也就是上面if save_csv下方的代码,这个是把检测结果的类别和坐标保存到一个txt文件,这里我们也不需要
删减前后结果对比如下2张图:
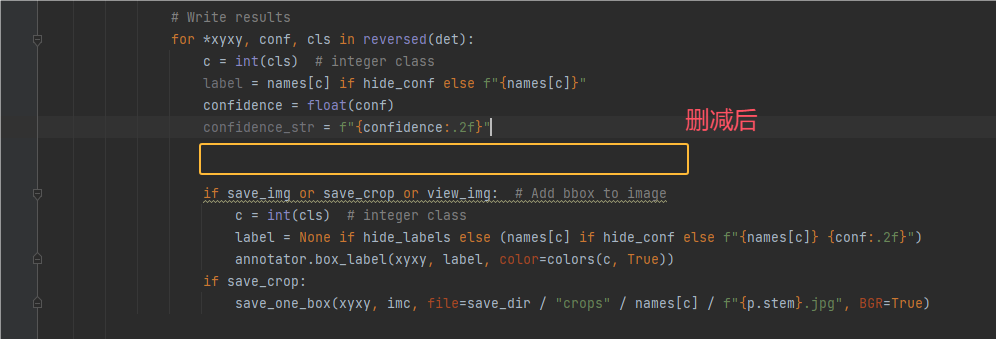
4.定位到 if view_img:,这个是用来供人查看图片的,我们也不需要
删减前后对比结果如下2张图:
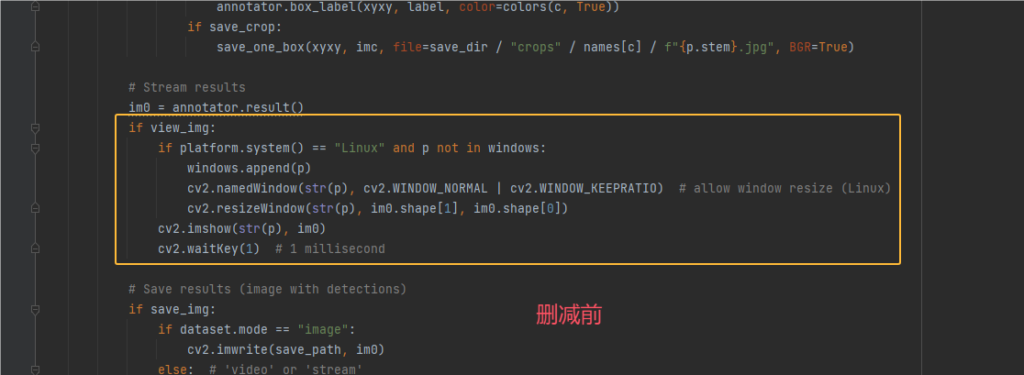
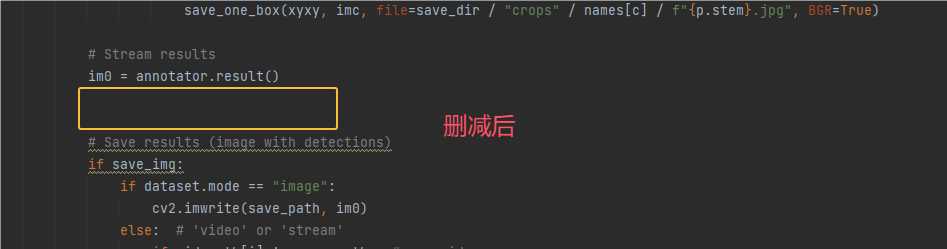
5.定位到 if vid_path[i] != save_path: ,这个处理视频文件,我们也不需要
删减前后对比结果如下2张图片
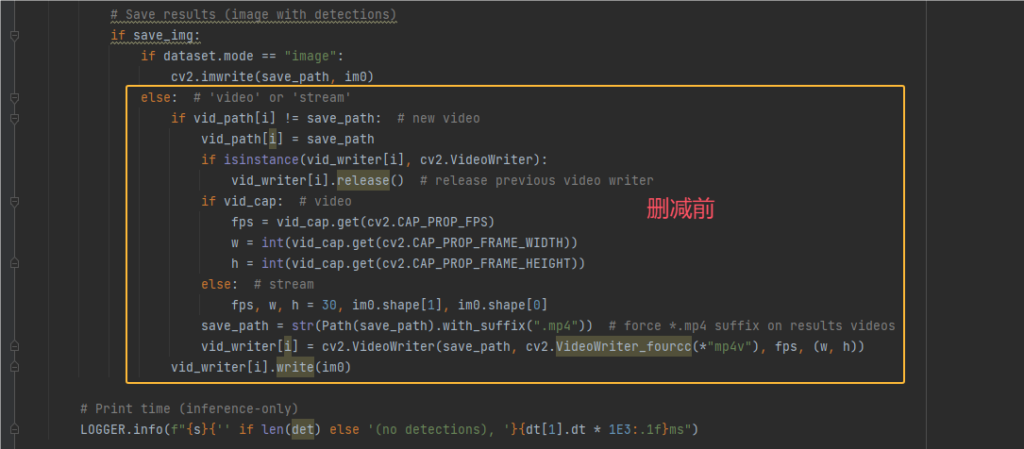
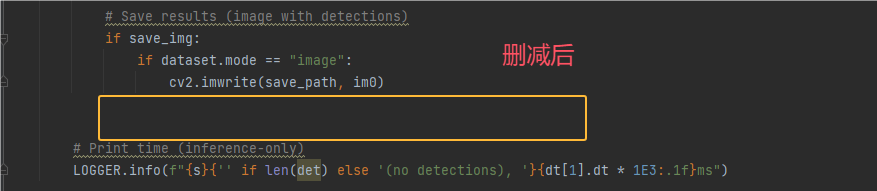
提示:删完后可以再次执行下detect.py,看结果是否和最开始测试的是否一致,若一致则没问题,否则你可能删除了不该删的代码。
步骤3:修改detect.py
思路:我们期望调用识别接口后,能够返回识别出的类别信息、方框坐标信息、识别耗时(ms)、以及生成的画框后的图片文件路径,这里我们的模型文件主要是针对一个缺陷类别,因此能保证返回的类别只有一个,但是图片中可能有多个缺陷,所以方框坐标是会有多个的,因此我们最终返回的数据定位如下JSON数据:
{
"class":"", //类别
"mark":[ //方框坐标
["x1","x2","y1","y2"],
["x1","x2","y1","y2"],
["x1","x2","y1","y2"]
],
"wasteTime":45.5, //识别图片耗时,单位毫秒ms
"markPath":"" //标记后的图片生成的路径
}
确定好返回的数据类型,然后来找类别、坐标、耗时、图片路径信息
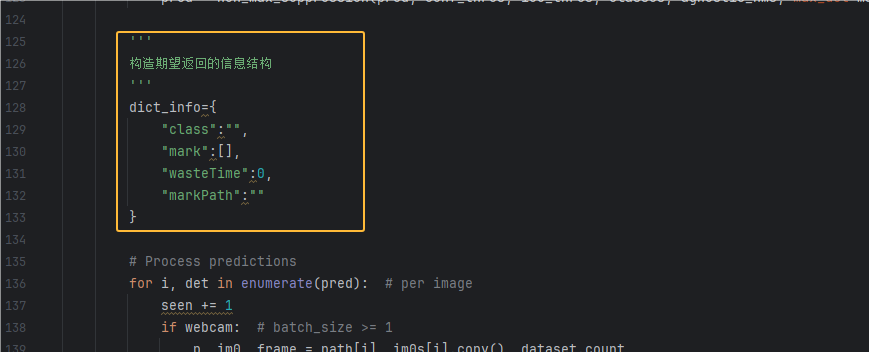
1.定位到 for i, det in enumerate(pred):,在其上方添加如下代码,用于保存返回的识别后的信息,如图:
注意:如果你用来一次性处理多张图片的话,这里定义的应当是个数组,本教程是用于调一次接口识别一张图的,因此定义的dict_info是个对象
'''
构造期望返回的信息结构
'''
dict_info={
"class":"",
"mark":[],
"wasteTime":0,
"markPath":""
}
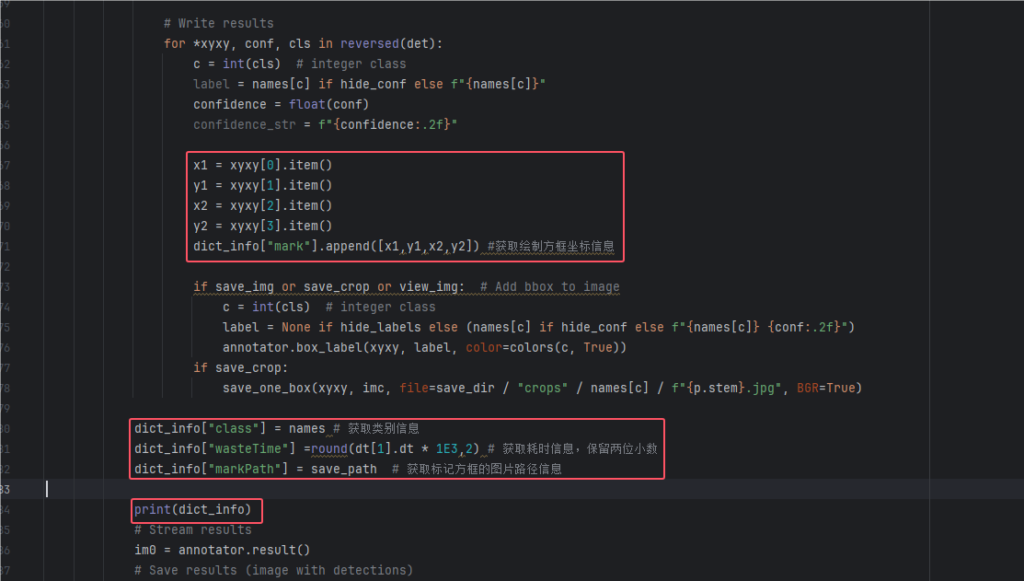
2.然后定位到 for *xyxy, conf, cls in reversed(det),在这里我们能获取到绘制方框的坐标信息,添加的代码为如下图中红色标记的,注意位置不要搞错了
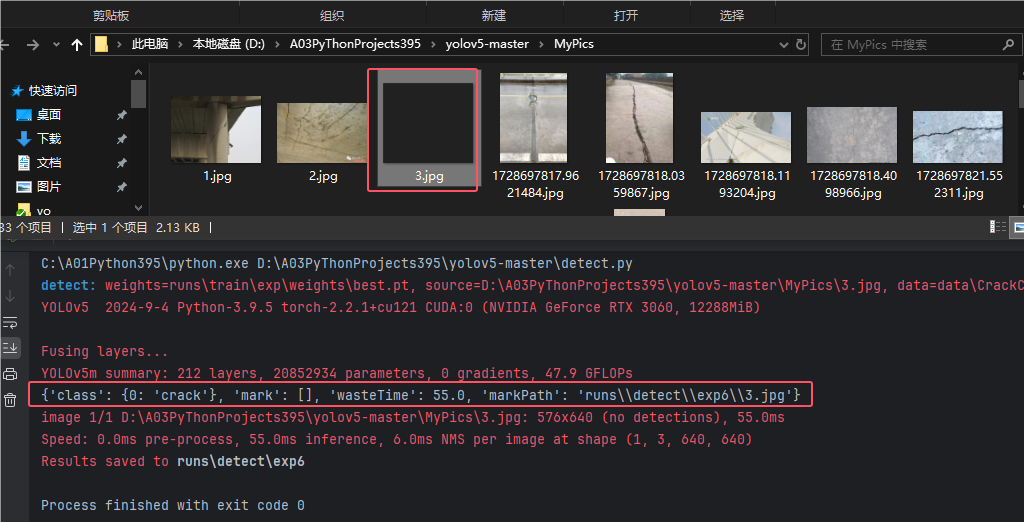
然后运行以下detect.py,可以看到相关信息都获取到了
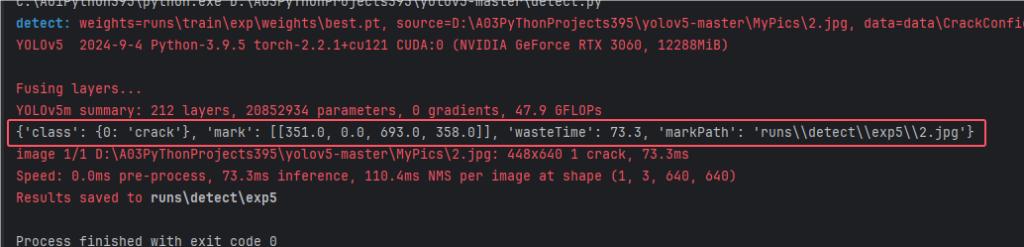
那如果假设没有识别出缺陷,这添加的代码会报错吗?
我们找个全黑色或者全白色的图片来测试下,如下图可以看见只是绘制坐标的数据为空,其他的信息依然是返回了的
步骤4:Flask整合为Web接口
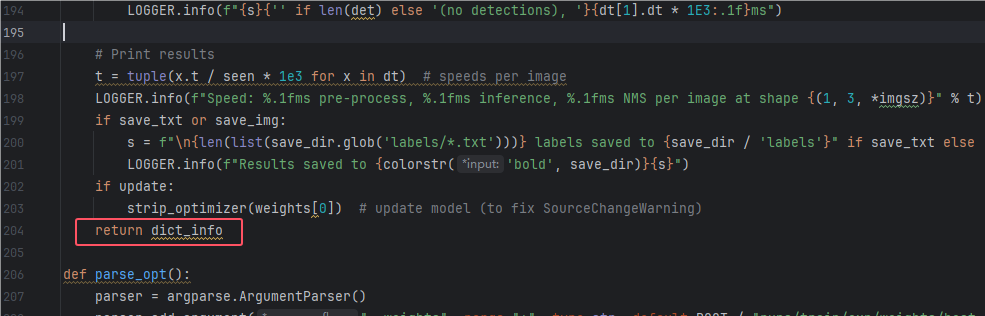
1.修改run函数,在run函数的最后一行添加 return dict_info,因为识别后的信息都在这个函数中,如图
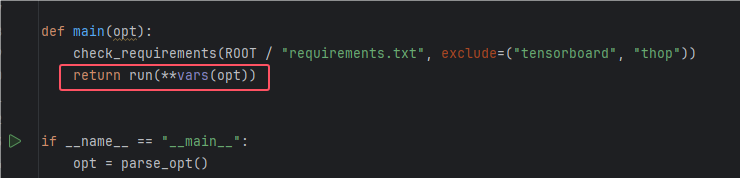
2.为main函数添加 return,因为main最后调用了run,如图
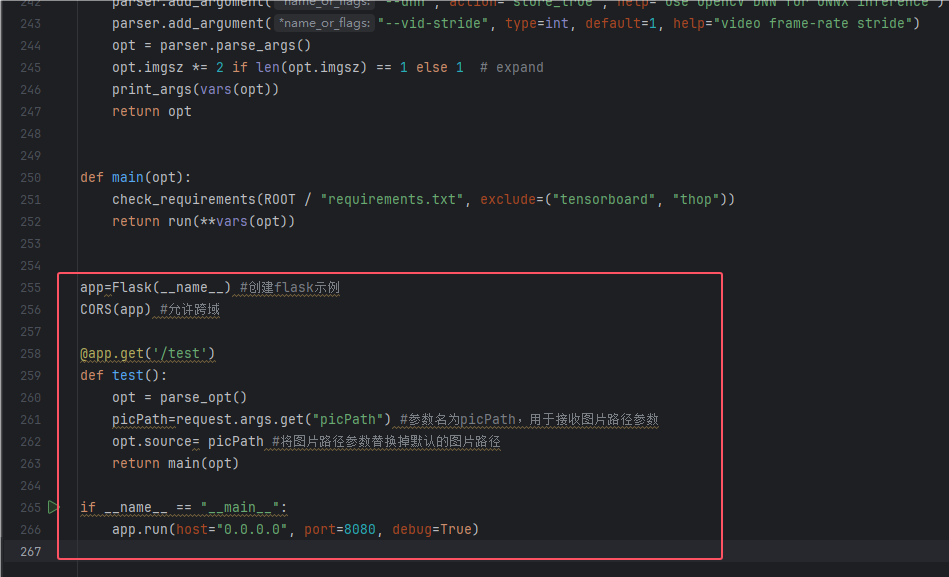
3.新增test函数作为Get接口,将main方法中的两行代码剪切给test函数,然后创建flask示例,将test函数改写为一个接收图片路径并调用main进行识别返回信息的接口,最后把 if name == “main”改写为允许flask的功能,代码和图如下
app=Flask(__name__) #创建flask示例
CORS(app) #允许跨域
.get('/test')
def test():
opt = parse_opt()
picPath=request.args.get("picPath") #参数名为picPath,用于接收图片路径参数(注意这里的request库是flask下的!!!)
opt.source= picPath #将图片路径参数替换掉默认的图片路径
return main(opt)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080, debug=True)
最后我们运行detect.py,可以看到flask服务启动了,端口为8080
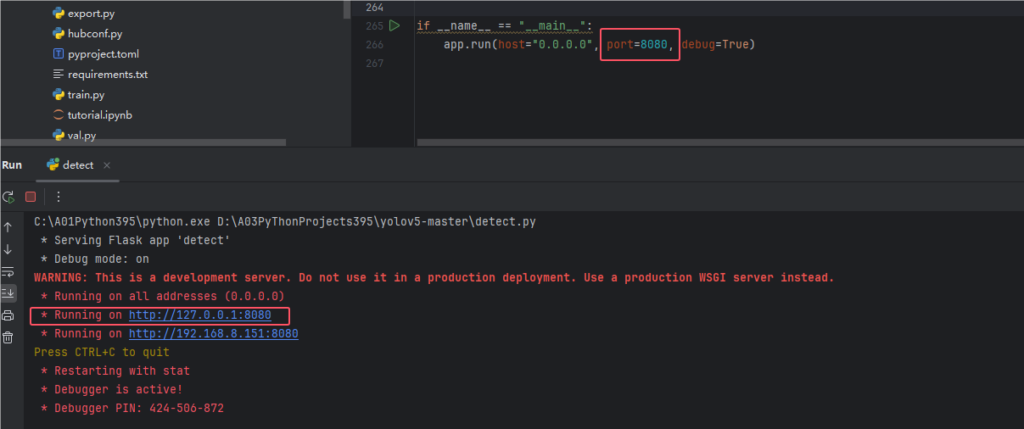
步骤5:模拟请求调用接口
这个接口比较简单,我们直接在浏览器中测试就行了,先找个裂缝图链接,百度图片右键可以复制图片链接,复制后在浏览器地址栏先看看能否使用,如图
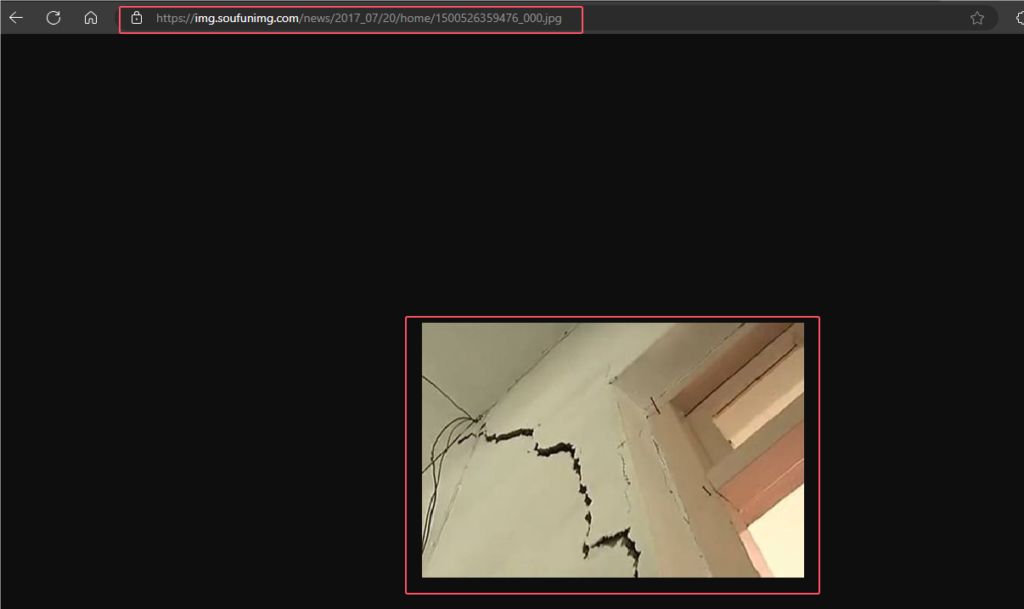
然后在浏览器地址栏直接请求我们的get接口,注意我们接口需要的参数名为picPath,将图片链接复制给picPath,因此我请求的路径为:
http://127.0.0.1:8080/test?picPath=https://img.soufunimg.com/news/2017_07/20/home/1500526359476_000.jpg
然后回车,就可以看到识别的结果,如图
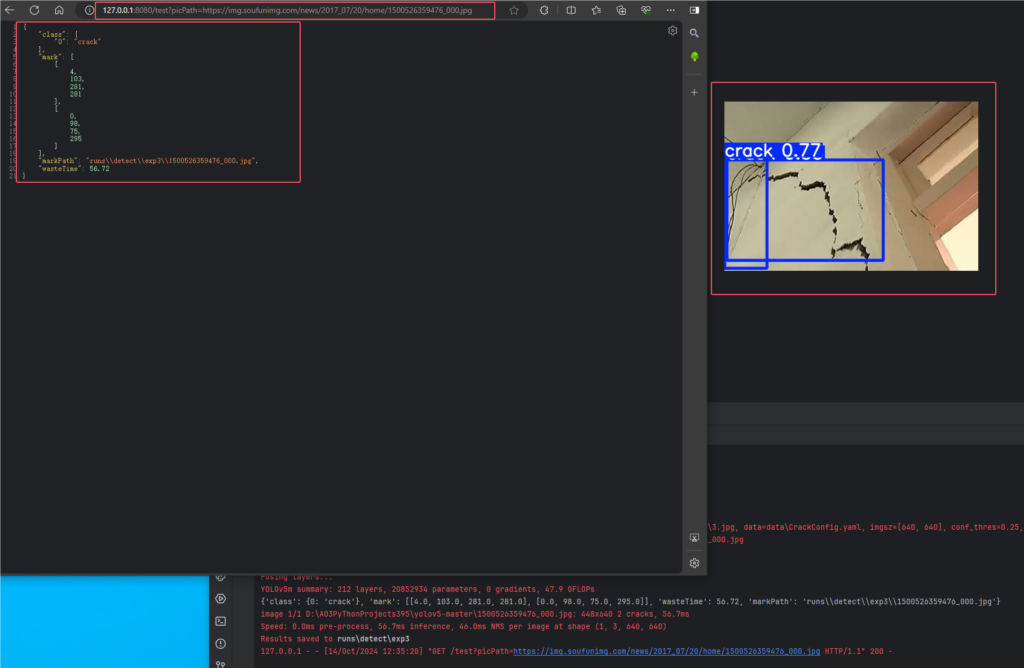
至此,一个图像识别接口就完成了,当然这里是单张图识别的接口,可自行改写为多张图识别返回信息的






暂无评论内容