

文章概述
本文讲述了一个由于多关联查询导致785条数据查询耗时2秒的问题,并通过查找问题->分析问题->解决问题的步骤,利用MySQL建立索引,将接口耗时由2秒缩减到115毫秒。
问题描述
在一个前端界面中,有785条数据,数据来自于分页查询接口,如下图可以看到apifox的测试,从785条数据中查询50条数据,耗时有2秒左右,这显然问题很大

问题查找
接口的业务逻辑代码量行数一般很多,不可能每行代码都加上输出语句来记录耗时,这显然不合理,因此这里使用arthas来追踪耗时问题所在,步骤为如下
启动项目->启动arthas->监控我的java项目->追踪方法->apifox调用接口三次
如图,可以看到在该方法中很明显的可以看到问题出现在TaskDao:findPage()方法和TaskDao:findCountByCondition()方法,分别耗时1.22秒与0.77秒左右,看来是SQL语句造成的问题

分析问题
在findPage()方法中,Mapper的SQL语句如下,我们先来解决这个问题
<select id="findPage" resultType="com.uav.task.domain.vo.TaskListVO">
SELECT
t.id AS id,
tgrp.guide_name as lineName,
t.task_number AS taskNumber,
t.task_name AS taskName,
t.start_time AS startTime,
t.end_time AS endTime,
GROUP_CONCAT(DISTINCT tgrp.facility_name SEPARATOR ', ') AS inspectionRanges,
GROUP_CONCAT(DISTINCT u.username) AS executors,
COUNT(DISTINCT CASE WHEN infa.is_execute = 1 THEN infa.id END) AS executed,
COUNT(DISTINCT infa.id) AS facilityTotal,
COUNT(DISTINCT fapi.id) AS picture,
COUNT(DISTINCT fapi.id) AS identifyTotal,
COUNT(DISTINCT CASE WHEN fapi.is_identify = 1 THEN fapi.id END) AS identified
from task t
left join inspection_facility infa on infa.fk_task_id=t.id
left join facility_pics fapi on fapi.fk_inspection_facility_id=infa.id
left join facility fa on fa.id=infa.fk_facility_id
left join user u on FIND_IN_SET(u.id,infa.executor_ids)
left join task_guide_rule_point tgrp on tgrp.fk_task_id=t.id and tgrp.fk_facility_id=infa.fk_facility_id
LEFT JOIN line l ON t.fk_guide_id = l.id
<where>
<if test="keyword != null and keyword != ''">
and t.task_number=#{keyword}
</if>
<if test="lineName != null and lineName != ''">
and tgrp.guide_name LIKE CONCAT('%', #{lineName}, '%')
</if>
</where>
group by t.id
ORDER BY t.create_time DESC
limit #{page},#{size}
</select>我这里将where去掉,将limit设置为1,50,改为原始SQL语句,并利用EXPLAIN来分析数据库是如何执行这条语句的,原始sql如下
EXPLAIN
SELECT
t.id AS id,
tgrp.guide_name AS lineName,
t.task_number AS taskNumber,
t.task_name AS taskName,
t.start_time AS startTime,
t.end_time AS endTime,
GROUP_CONCAT(DISTINCT tgrp.facility_name SEPARATOR ', ') AS inspectionRanges,
GROUP_CONCAT(DISTINCT u.username) AS executors,
COUNT(DISTINCT CASE WHEN infa.is_execute = 1 THEN infa.id END) AS executed,
COUNT(DISTINCT infa.id) AS facilityTotal,
COUNT(DISTINCT fapi.id) AS picture,
COUNT(DISTINCT fapi.id) AS identifyTotal,
COUNT(DISTINCT CASE WHEN fapi.is_identify = 1 THEN fapi.id END) AS identified
FROM task t
LEFT JOIN inspection_facility infa ON infa.fk_task_id = t.id
LEFT JOIN facility_pics fapi ON fapi.fk_inspection_facility_id = infa.id
LEFT JOIN facility fa ON fa.id = infa.fk_facility_id
LEFT JOIN user u ON FIND_IN_SET(u.id, infa.executor_ids)
LEFT JOIN task_guide_rule_point tgrp ON tgrp.fk_task_id = t.id AND tgrp.fk_facility_id = infa.fk_facility_id
LEFT JOIN line l ON t.fk_guide_id = l.id
GROUP BY t.id
ORDER BY t.create_time DESC
LIMIT 1, 50;在navicat中执行该语句,结果如下图

在上面的结果中可以看到问题有如下
-
type: ALL)(影响最大) -
使用临时表和文件排序(
Using temporary; Using filesort) -
使用
Block Nested Loop连接 -
FIND_IN_SET的低效性
解决方案
针对以上问题,可以从索引、查询逻辑、聚合函数进行优化,但其实全表扫描是最大问题,因此从索引建立入手
索引建立
由图表结果可以看到影响最大的是infa、tgrp,这里要注意,我这个表的主键id,是由uuid生成的,因此索引是不生效的,不用管,其次fa表虽然rows列看起来少,但其实该表是一个图片表,只是数据量少,因此最终可知需要加索引的有infa、tgrp、fa三张表
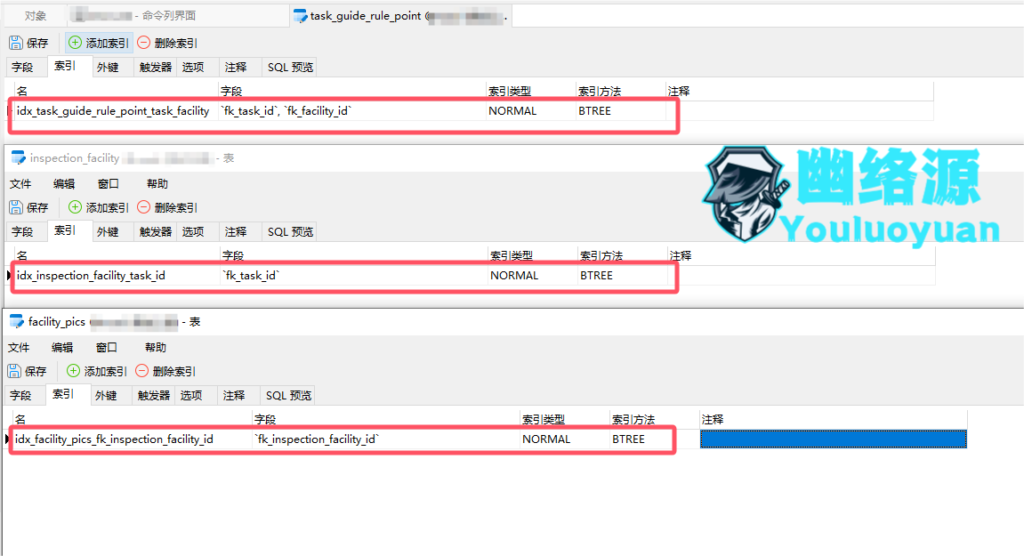
和fk_facility_id,且需要将 fk_task_id 放在前面,fk_facility_id 放在后面。因为fk_task_id 是 JOIN
再次测试
索引建立后,还是先使用EXPLAIN对sql语句进行解释,查看索引是否生效,如下图可以看到infa、fapi、tgrp的type由all变为了ref表示从全表扫描变为了索引扫描,extra列也变为了null,表示不再有其他额外的操作

那么真的能提高速度吗?
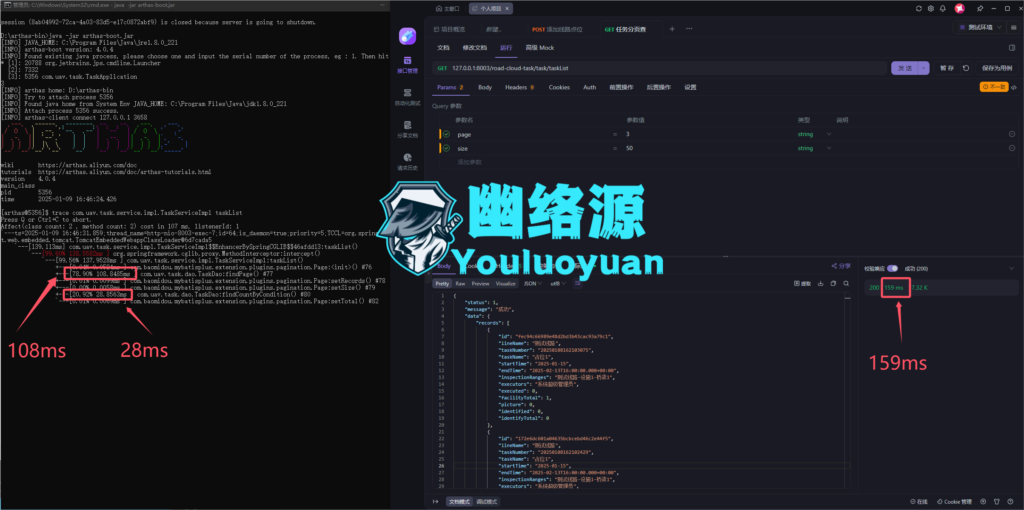
启动项目,使用apifox再次测试该接口,当然arthas也可以启动进行监控耗时,如下图可以看到,apifox中接口响应时间由原来的2秒左右变为了150ms,arthas中findPage与findCountByCondition也分别由原来的1200ms、770ms缩减到100ms、28ms,优化很成功
结语
以上是幽络源的使用arthas查找分页接口耗时原因并建立MySQL索引优化接口响应速度的教程,如有疑问可留言,加入我们的java学习QQ群307531422随时随地解决问题,一起交流学习。






暂无评论内容