

教程概述
本教程先是幽络源初步教学分析掌阅书籍的网络结构,最后提供完整的爬取源码与使用说明,并展示结果,切记勿将本教程内容肆意非法使用。
确定目标
第一次做,就先随便找一本的某一页作为目标
任意选择一本进入到任意一页,通过开发人员工具,也就是F12,在元素中可以看到页面中的内容实际为引入的iframe,如图
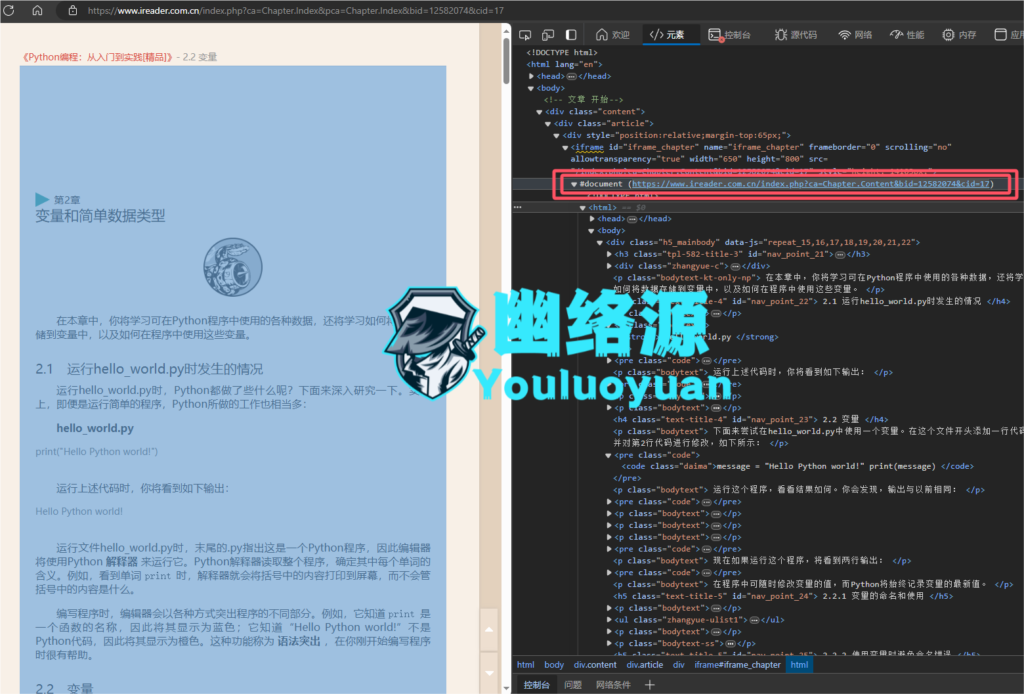
复制这个iframe链接,在另一个页面打开,可以看到,确实为书中的内容,如图
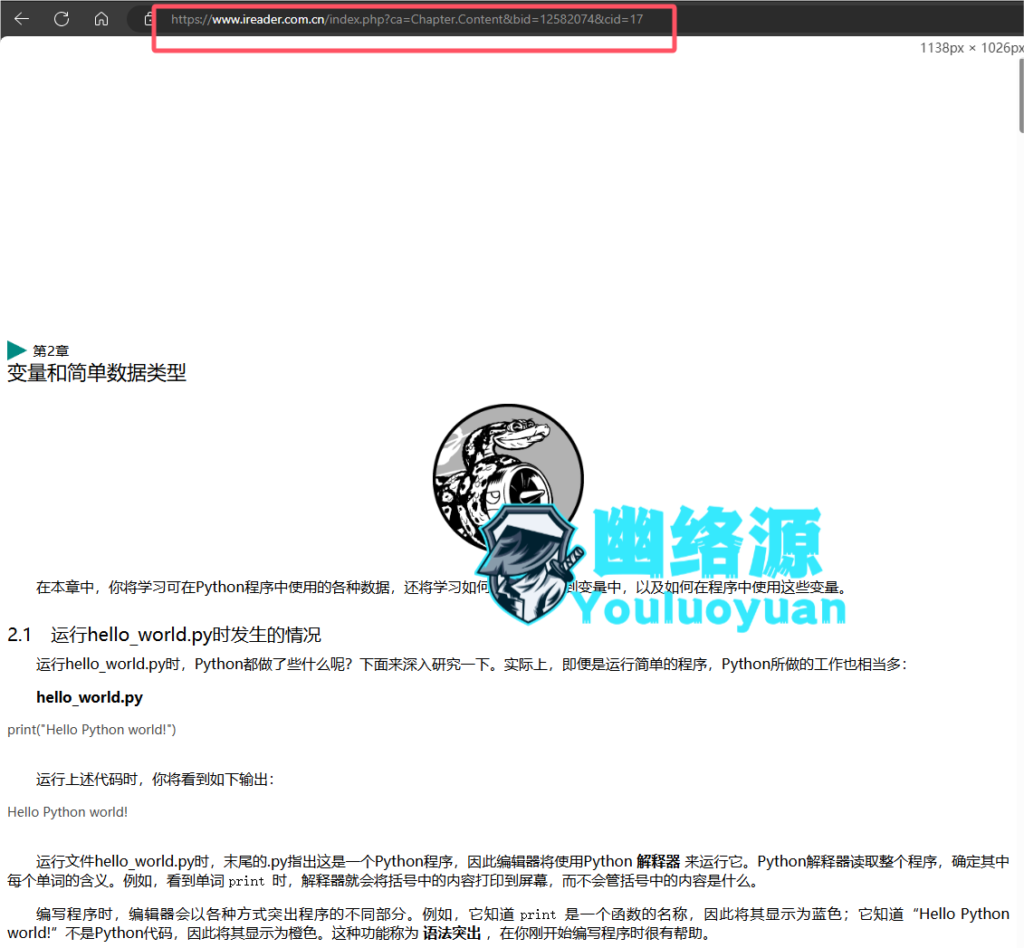
确定使用什么库
同样的打开开发人员工具,然后刷新网页,在网络中可以看到,响应的是一个html页面,而不是像json一样的数据,也不是js内容,因此我们此次爬取应当是用requests_html库,如图
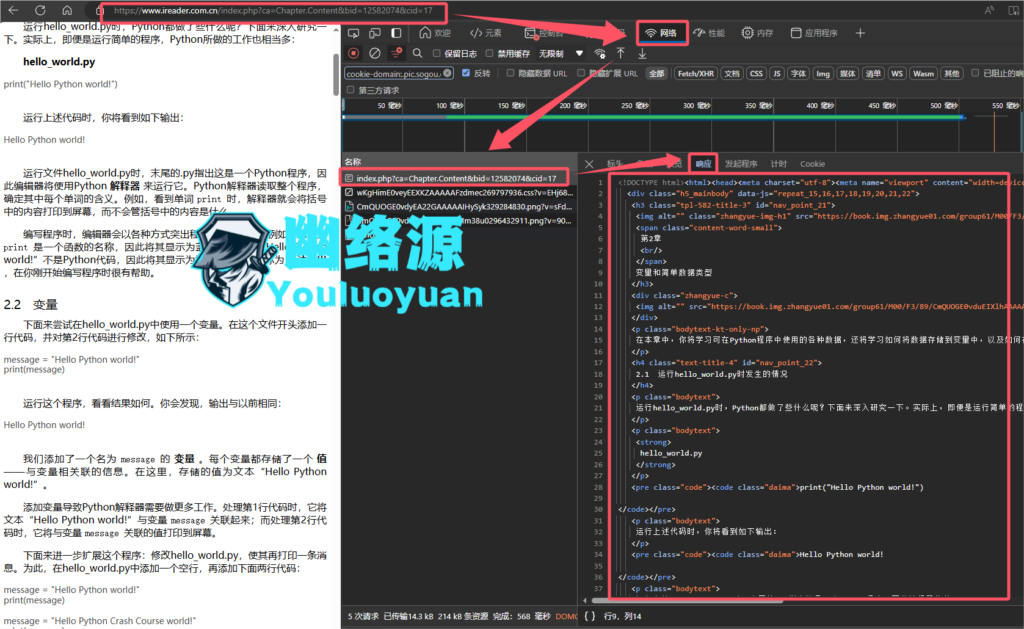
分析页面
在元素栏,我们大致看下页面用到了什么标签,如图,可以看到还不少,特别对于这种编程类的书,可能小说类的书标签没这么复杂、繁多,包括了
h1~h5、div、p、pre、code、ul、img、strong,如图
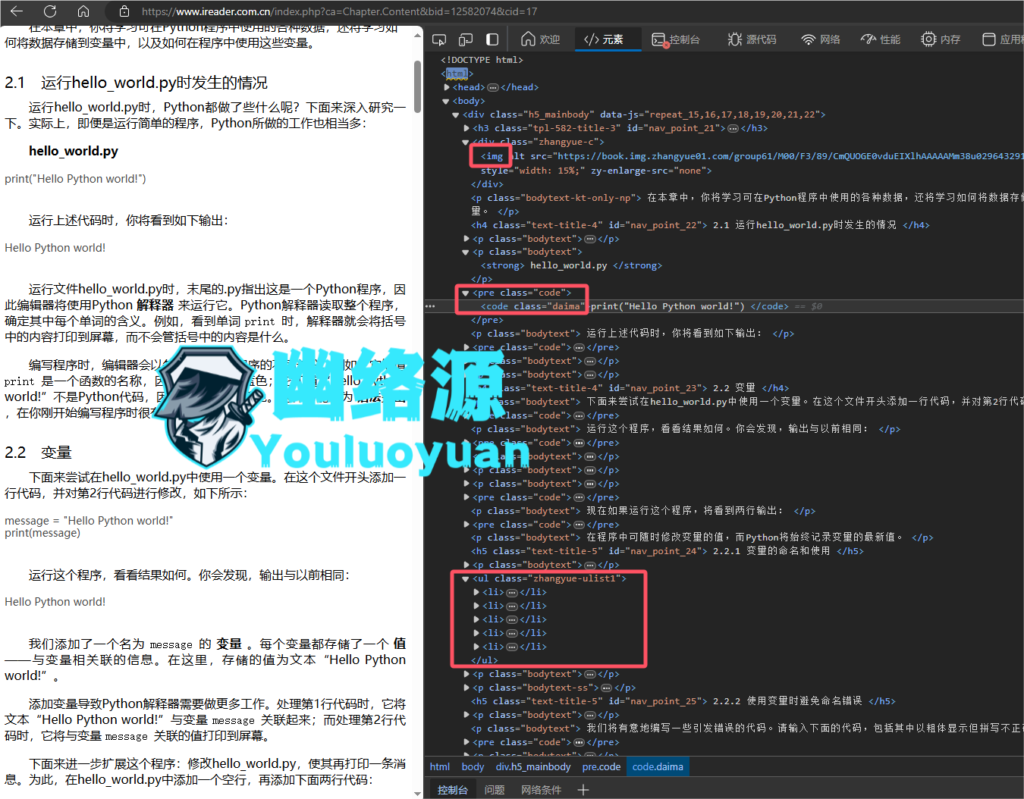
爬取页面测试
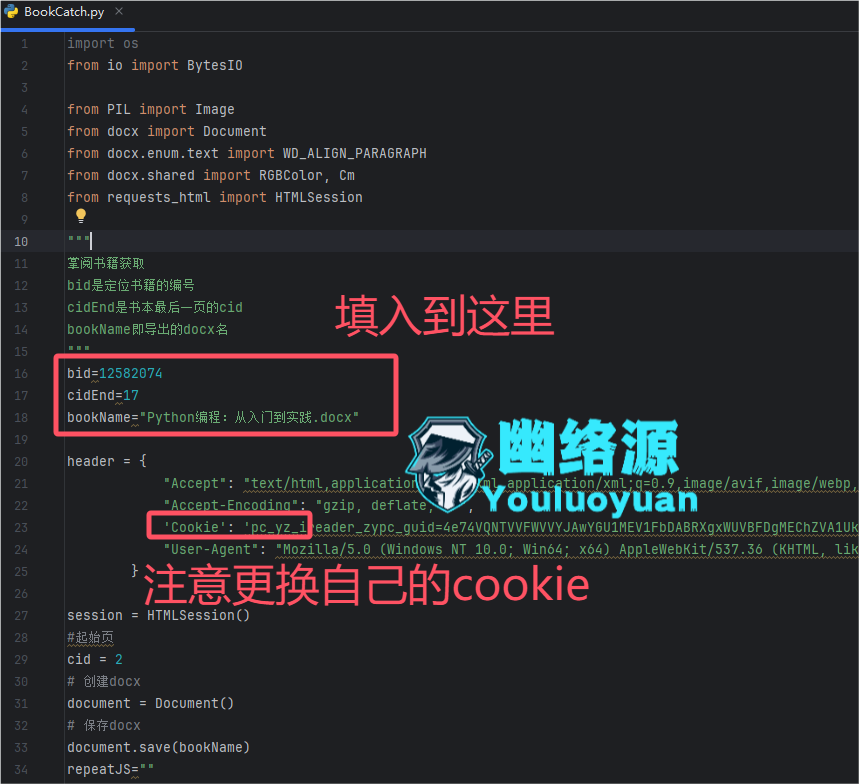
导入requests_html,简单的爬取下当前页面,看看是否有结果,注意headers中请务必替换为自己的Cookie,这个是用户登录掌阅后,个人的Cookie,而且是会失效的,代码与图如下
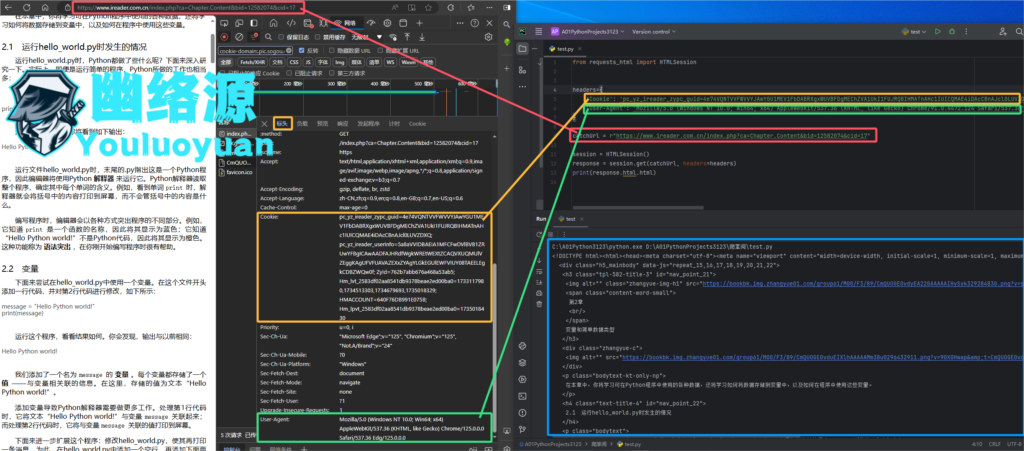
from requests_html import HTMLSession
headers={
'Cookie': 'pc_yz_ireader_zypc_guid=4e74VQNTVVFWVVYJAwYGU1MEV1FbDABRXgxWUVBFDgMEChZVA1UkI1FUJRQBIHMATnAHc1IUICQMAE4iDAcCBnAJcl0LUVZDXQ; acw_tc=ac11000117345133024156602e0092fe3024a7908746542deb2cde133dcf3d; ZyId=53f28cda676292968b316; Hm_lvt_2583df02aa8541db9378beae2ed00ba0=1732523971,1733117980,1734513303; HMACCOUNT=640F76DB991E075B; pc_yz_ireader_userInfo=5a8aVVIDBAEIA1MFCFwDVlBVB1ZRUwYFBgICAwAADFAJHRdfWgkWREtWEXtZCAQVXUQMUlVZEggKAgUFVFUAVAZEXxZYAgYLGkEGUlEWFVIUY08TAEELEgkCDBZWQw0f; Hm_lpvt_2583df02aa8541db9378beae2ed00ba0=1734513504', # 将 'your_cookie_here' 替换为实际的 Cookie 值
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
catchUrl = r"https://www.ireader.com.cn/index.php?ca=Chapter.Content&bid=12582074&cid=17"
session = HTMLSession()
response = session.get(catchUrl, headers=headers)
print(response.html.html)通过如上代码,我们获取了当页的元素信息并输出到了控制台,下面来逐步解析标签,结合python-docx库,将爬取的信息存入到word中
分析标签并输出
在<body>中可以看到所有内容其实都在一个class为h5_mainbody的div标签中,因此可以粗略的直接获取该div下的所有元素,代码与图如下
session = HTMLSession()
response = session.get(catchUrl, headers=headers)
eles=response.html.find(".h5_mainbody *")
for ele in eles:
print(ele) #输出每个元素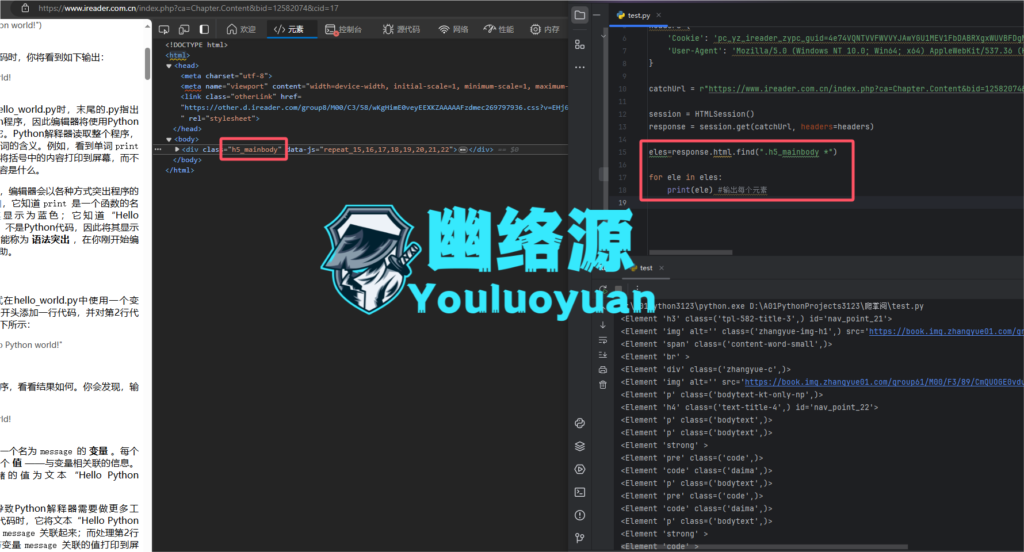
完整源码与使用方式
完整源码
行数有点大,这里就不直接贴出了,我保存在了夸克盘中(请勿肆意非法使用),完整源码见链接:
https://pan.quark.cn/s/c865bd395ef4
使用方式:
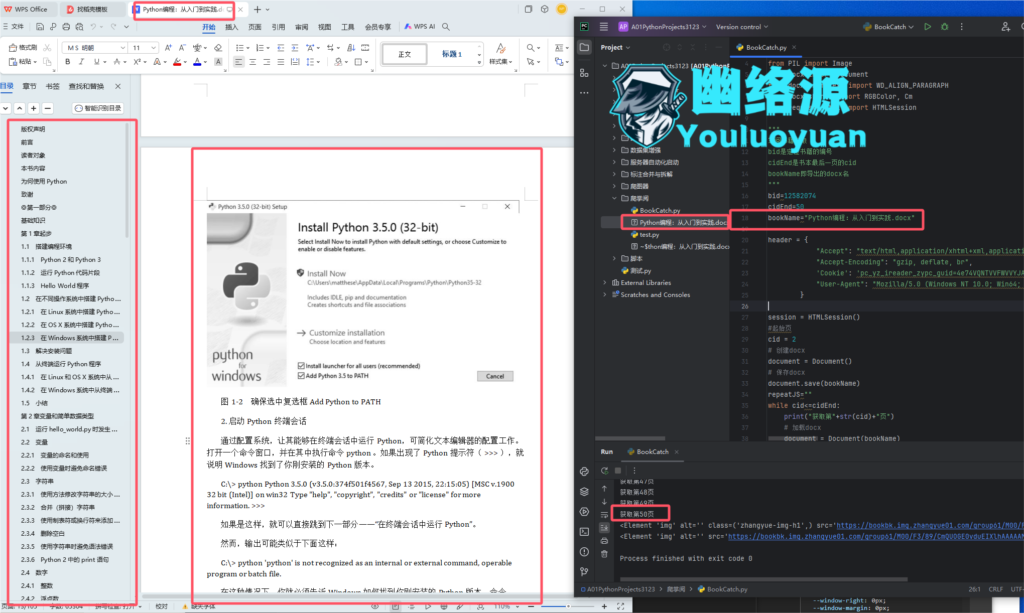
如图,我这里以爬取《Python编程:从入门到实践》为例子
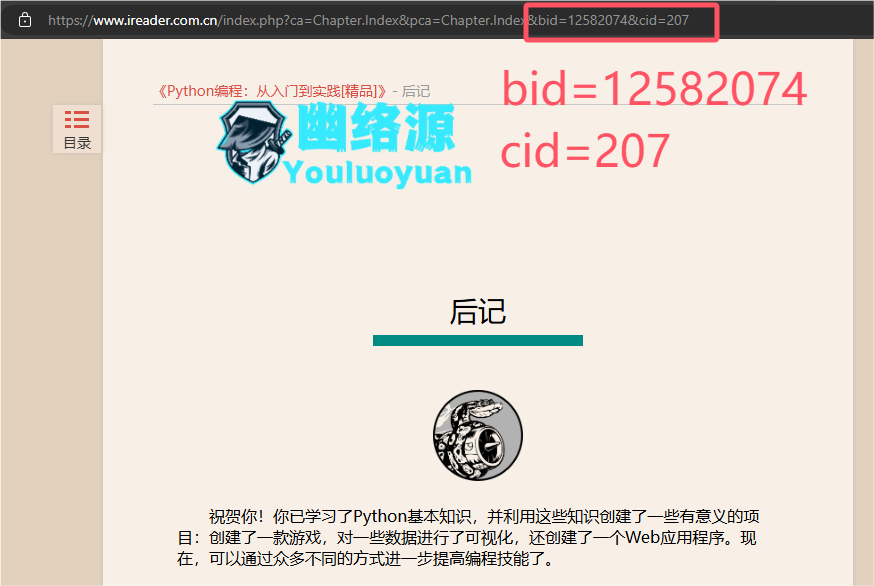
可以看到本书的bid为12582074
最后一页的cid为207
因此我将这三个参数填入到源码中
此外,特别需注意的是cookie也要填入自己的,如图
爬取结果
为了演示,我这里只爬取了50页,结果如图,可以看到,书本内容完整的爬取到了word中,且根据标题做了分级,还是很不错的
总结建议
在这个爬取源码中,算是比较良好,能完整的爬取所有内容,我个人认为不足的是图片处理还需优化,代码中的图片处理是直接获取的原图,为了美观,应当根据css来决定图片的大小,以上是幽络源的python使用requests_html库爬取掌阅的分析教程与完整源码提供,如有疑问,可加群询问,如有其他需求可站内留言。






暂无评论内容