

前言
往往在准备需要训练一个模型的时候,很多人苦于找不到合适的数据集,自己标注又耗时耗力,而数据增强正好解决了这个问题,因此对于数据增强这个概念是非常有必要的,本文将提供一个数据增强脚本,你无需理解代码,只需懂得如何使用即可达到你要的效果。
背景
近期我在一直寻找冲沟相关的Box标注数据集,结果是收费的与不收费的都没有找到,唯一找到的和冲沟相关还是一个图像分类的数据集,不是Box标注的对象识别的,如下图
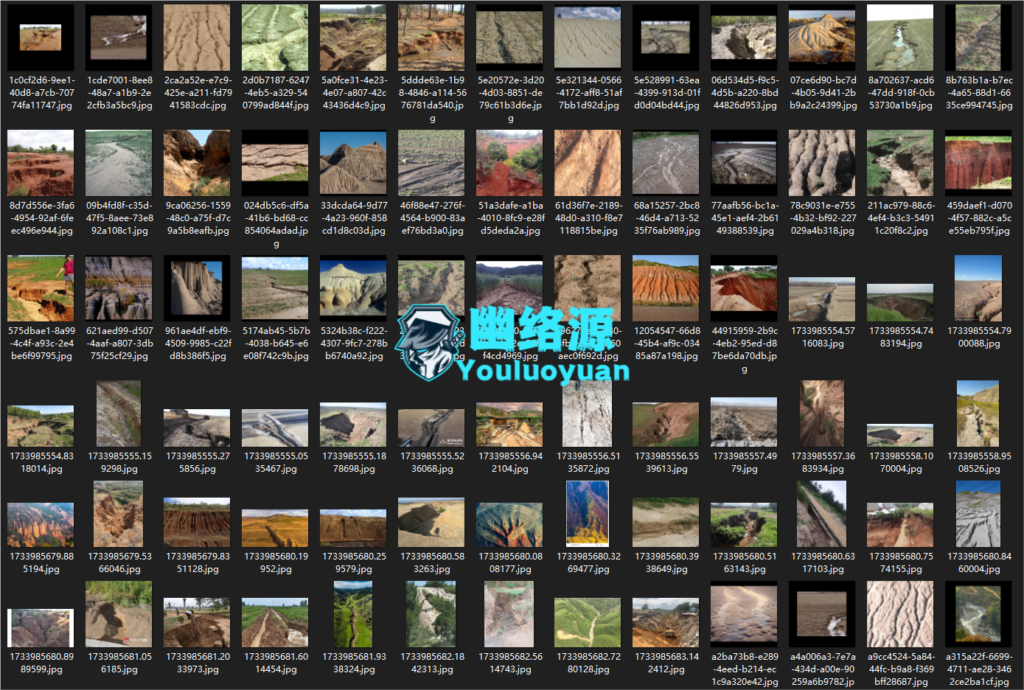
以上图片其实很符合冲沟相关的特征与缺陷,只是这些图没有被标注,那就只有自己标注了,标注完后,前前后后加起来也才125张,这点数据量相对于这种复杂的地貌和缺陷是远远不够的,因此我突然想起一个数据增强的概率,或许会有用(我是外行)。
图片数据增强脚本
先直接上源码,然后再说使用方式
import os
import cv2
import albumentations as A
from tqdm import tqdm
# 数据增强脚本
def augment_images_and_labels(img_dir, label_dir, output_img_dir, output_label_dir, val_img_dir, val_label_dir, augment_times=3):
"""
对YOLO数据进行安全的数据增强。
:param img_dir: 原始图片的目录路径
:param label_dir: YOLO标签目录路径
:param output_img_dir: 增强后的图片保存目录
:param output_label_dir: 增强后的标签保存目录
:param val_img_dir: 第一个增强图片存放的目录,用于验证集
:param val_label_dir: 第一个增强标签存放的目录,用于验证集
:param augment_times: 每张图片的增强次数
"""
# 确保输出目录存在
os.makedirs(output_img_dir, exist_ok=True)
os.makedirs(output_label_dir, exist_ok=True)
os.makedirs(val_img_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
# 遍历图片和标签
for img_file in tqdm(os.listdir(img_dir)):
if not img_file.endswith(('.jpg', '.png', '.jpeg')):
continue
# 获取文件路径
img_path = os.path.join(img_dir, img_file)
label_path = os.path.join(label_dir, os.path.splitext(img_file)[0] + '.txt')
# 读取图像
image = cv2.imread(img_path)
if image is None:
print(f"无法读取图像: {img_path}")
continue
height, width = image.shape[:2]
# 读取YOLO标签
bboxes = []
class_labels = []
if os.path.exists(label_path):
with open(label_path, 'r') as f:
for line in f.readlines():
parts = line.strip().split()
class_id = int(parts[0])
x_center, y_center, w, h = map(float, parts[1:])
bboxes.append([x_center, y_center, w, h])
class_labels.append(class_id)
# 原始标签检查
if not bboxes:
print(f"标签为空: {label_path}")
continue
# 进行数据增强
for i in range(augment_times):
# 动态调整裁剪区域大小(最大不能大于图像尺寸)
min_crop_size = min(height, width)
crop_height = min(500, min_crop_size)
crop_width = min(500, min_crop_size)
# 更新增强方法中的裁剪尺寸
augmentations = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.Rotate(limit=10, p=0.5, border_mode=cv2.BORDER_CONSTANT),
A.GaussianBlur(p=0.2),
A.GaussNoise(p=0.2),
A.Resize(width=640, height=640, p=0.5),
A.RandomCrop(width=crop_width, height=crop_height, p=0.5),
A.HueSaturationValue(hue_shift_limit=20, sat_shift_limit=30, val_shift_limit=20, p=0.5),
A.ElasticTransform(p=0.2),
A.RandomScale(p=0.2),
], bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
augmented = augmentations(image=image, bboxes=bboxes, class_labels=class_labels)
aug_image = augmented['image']
aug_bboxes = augmented['bboxes']
aug_labels = augmented['class_labels']
# 如果是第一个增强,保存到验证集目录
if i == 0:
output_img_path = os.path.join(val_img_dir, f"{os.path.splitext(img_file)[0]}_aug_0.jpg")
output_label_path = os.path.join(val_label_dir, f"{os.path.splitext(img_file)[0]}_aug_0.txt")
else:
# 否则,保存到训练集目录
output_img_path = os.path.join(output_img_dir, f"{os.path.splitext(img_file)[0]}_aug_{i}.jpg")
output_label_path = os.path.join(output_label_dir, f"{os.path.splitext(img_file)[0]}_aug_{i}.txt")
# 保存增强后的图片
cv2.imwrite(output_img_path, aug_image)
# 保存增强后的标签
with open(output_label_path, 'w') as f:
for bbox, cls in zip(aug_bboxes, aug_labels):
x_center, y_center, w, h = bbox
f.write(f"{int(cls)} {x_center} {y_center} {w} {h}\n")
print("数据增强完成!")
if __name__ == "__main__":
# 输入目录路径,必须是全英文路径
img_dir = r"D:\A01PythonProjects3123\labelImg-master\gullyYolo\images" # 原始图片路径
label_dir = r"D:\A01PythonProjects3123\labelImg-master\gullyYolo\labels" # YOLO标签路径
# 输出目录路径
output_img_dir = "handleImages" # 保存增强后图片路径
output_label_dir = "handleLabels" # 保存增强后标签路径
# 验证集目录路径
val_img_dir = "val_images" # 保存增强后验证集图片路径
val_label_dir = "val_labels" # 保存增强后验证集标签路径
# 执行数据增强
augment_images_and_labels(img_dir, label_dir, output_img_dir, output_label_dir, val_img_dir, val_label_dir, augment_times=8)使用方式
对于以上的源码,你唯一需要修改的便是 main方法中的img_dir与label_dir的路径,分别为你需要增强的图片目录路径和图片对应的标签目录路径。输出目录和验证集目录不用修改,然后你可以通过修改 augment_images_and_labels函数中的augment_times的次数,这个次数决定了增强的次数,每次增强都是不一样的效果。
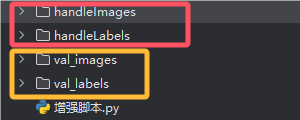
确定好这些即可执行脚本完成数据的增强,如图,执行后输出了四个目录,红框中的两个目录作为训练集使用,黄框中的两个目录作为验证集使用
我这里的次数设定为了8,最终handleImages的目录中的图片如下

虽然次数为8,但是这作为训练集的每张图只具备了7张,因为还有一张作为了验证集,这样能保证每一张图都能得到好的训练+验证,并且我的图片由原来的125张变为了现在的984张
本脚本优势
增强操作多样
- 使用了
albumentations库,支持多种常见的图像增强操作,如:- 水平翻转 (
HorizontalFlip) - 亮度与对比度调整 (
RandomBrightnessContrast) - 旋转 (
Rotate) - 高斯模糊 (
GaussianBlur) - 高斯噪声添加 (
GaussNoise) - 随机裁剪 (
RandomCrop) - 色调、饱和度、亮度调整 (
HueSaturationValue) - 弹性变换 (
ElasticTransform) - 随机缩放 (
RandomScale)
- 水平翻转 (
验证集与训练集区分
- 在增强过程中,第一个增强样本(即
i == 0)被保存到专门的验证集目录(val_img_dir和val_label_dir),其余增强样本被保存到训练集目录(output_img_dir和output_label_dir)。这种做法保证了验证集与训练集数据的区分,避免验证集样本被重复用于训练。 - 具体来说:
- 第一个增强样本:保存为验证集数据。
- 后续增强样本:保存为训练集数据。
动态裁剪大小调整
- 脚本中对于裁剪操作的尺寸进行了动态调整,确保裁剪区域的大小不会超过原始图像的实际尺寸。这保证了在进行裁剪时不会丢失图像中的关键信息,特别是小尺寸的图像。
可定制的增强次数
- 每张图片可以进行多次增强,增强次数由
augment_times参数控制,默认值为3。用户可以根据需求调整这个值,以控制最终生成的增强数据量。
数据增强的好处
1. 增加数据多样性
- 数据增强能够通过对已有数据进行各种变换(如旋转、缩放、裁剪、翻转、颜色变化等),生成多样的训练样本。这能够帮助模型学习到不同的图像变换,不仅仅依赖于原始样本,从而让模型在面对不同的图像时更加稳健。
- 例如,通过翻转、旋转和裁剪,模型能学到不依赖于图像的特定方向、尺寸或位置的特征。
2. 提升模型的泛化能力
- 通过增加训练数据集的多样性,数据增强可以有效避免模型过拟合。过拟合是指模型在训练数据上表现良好,但在新的、未见过的数据上表现较差。
- 通过数据增强,模型能够在多种变形、噪声等情况下进行训练,从而更好地适应现实中多变的情况。
3. 提高模型对噪声的鲁棒性
- 数据增强中的噪声添加、模糊、随机遮挡等操作能够帮助模型在面对现实环境中的噪声时,依然保持较高的准确度。例如,Gaussian噪声和高斯模糊可以模拟摄像头拍摄过程中可能出现的模糊、失真等问题。
- 增强后的数据包含了不同种类的噪声,模型因此能够学会从噪声中提取有效信息,提高鲁棒性。
4. 扩展训练数据集
- 在数据较少的情况下,数据增强是增加训练数据的一种有效方式。很多时候,获取新的标注数据非常困难和昂贵,而通过增强现有数据,可以在不增加人工标注的情况下大幅扩充训练集。
- 数据增强可以显著增加训练数据量,避免数据集过小带来的训练困难,尤其在数据量有限的情况下尤为重要。
5. 应对标签稀缺问题
- 在某些任务中,标签数据非常稀缺(例如,医学影像分类、异常检测等),而通过数据增强,可以有效扩大可用标签数据的范围,进而帮助模型从有限的标签数据中学习更好、更全面的特征。
6. 优化数据质量
- 数据增强不仅仅是“增加”数据,还可以通过一些操作(如裁剪、平移、颜色调整等)去掉无用的信息,帮助模型更专注于关键部分,优化模型的学习过程。
- 比如,随机裁剪、改变亮度、对比度等可以去除一些背景噪声,让模型更好地聚焦于目标对象。
7. 应对不平衡数据问题
- 在一些应用中,不同类别的样本数量可能不均衡,数据增强可以帮助增强稀缺类别的数据,进而缓解类别不平衡对模型性能的影响。例如,通过对少数类数据进行增强,可以减少少数类在训练过程中的“弱势”表现。
8. 模拟现实场景
- 数据增强可以模拟现实中的各种变化,如光照变化、天气变化(雨天、雾霾等)、不同的摄像机视角等。这样训练出来的模型在面对现实世界中的复杂情况时,会更加准确和鲁棒。
- 例如,通过颜色抖动模拟不同的光照条件,或使用旋转与平移模拟不同的拍摄角度。
9. 加速训练过程
- 虽然数据增强增加了训练数据量,但它通常能够提高训练的效率。因为在训练过程中,增强后的数据帮助模型避免过早的收敛,从而需要更多的迭代次数来达到更好的性能。
- 此外,数据增强还可以帮助模型找到更加稳定和有代表性的特征。
总结
以上是幽络源对数据增强的应用与理解,个人认为做数据集,数据增强是非常有必要的







暂无评论内容