

背景
下载了个别人提供的数据集,但是我只需要用到里边的某一个或者某两个类别,因此需要将其他类别的数据集,包括图片和标签删除,当然,这里的删除,并不是直接一一对应删除,因为一张图对应的标签文件中不只有一种类别。
大致步骤
- 1.分析数据集
- 2.必要的预处理
- 4.处理剩下的类别的标签索引
步骤1.分析数据集
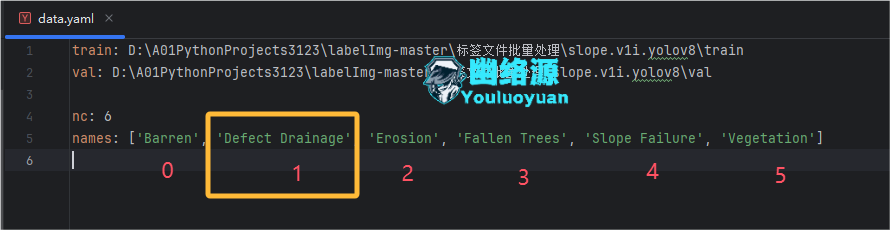
我拿了一个边坡相关的yolo数据集,配置文件如图,可以看到其中包含了6类对对象

翻译可知这六类对象为“贫瘠”、“排水缺陷”、“侵蚀”、“倒下的树木”、“斜坡坍塌”、“植被”,可以首先用LabelImg打开查看一下,由于我其实需要的是边坡堵塞相关的数据集,如图,这个排水缺陷的类型比较像,因此我这里以提取排水缺陷的数据集为例

步骤2.必要的预处理
在正式提取前,非常有必要做一些其他处理,特别是使用别人分享的数据集,比如检查是否包含了分隔标注,毕竟别人的数据集也不能拿来就用,可能是有问题的。
预处理一:规范文件名
比如文件名包含了多个后缀,例如名为 aaa.jpg.aaa.jpg 这种,处理方式见
Python批量修改YOLO数据集图片和标签名称为UUID – 幽络源教程 (youluoyuan.com)
预处理二:检查是否包含了分隔标注
我们这种矩形方框称为box标注,有些别人分享的数据集中可能会包含一些分隔标注的数据,这样混合起来的数据会对训练造成很大影响,虽然yolo自己会忽略掉,处理方式见
步骤3.使用脚本清理指定索引的类别
如图,根据yaml配置文件可知我这里需要提取的是索引为1的类别,即排水缺陷当作边坡(排水沟)堵塞缺陷
使用如下脚本,将索引为0,2,3,4,5的类别全部清除,执行后会将含有索引0,2,3,4,5的标签删除,而且标签文件对应索引信息删了后若文件为空还会将标签txt删除,且删除对应的照片
import os
# 目标目录路径
images_dir = r'D:\A01PythonProjects3123\labelImg-master\标签文件批量处理\slope.v1i.yolov8\train\images' # 图片文件目录
labels_dir = r'D:\A01PythonProjects3123\labelImg-master\标签文件批量处理\slope.v1i.yolov8\train\labels' # 标签文件目录
indices_to_remove = {0, 2, 3, 4, 5} # 要删除的类别索引
# 遍历labels目录下的所有文件
for filename in os.listdir(labels_dir):
file_path = os.path.join(labels_dir, filename)
if os.path.isfile(file_path) and filename.endswith('.txt'):
with open(file_path, 'r') as file:
lines = file.readlines()
# 过滤掉类别索引为0、2、3的行
filtered_lines = [line for line in lines if int(line.split()[0]) not in indices_to_remove]
# 如果文件内容不为空,写回过滤后的内容
if filtered_lines:
with open(file_path, 'w') as file:
file.writelines(filtered_lines)
print(f'{filename}')
else:
# 如果标签文件为空,删除该标签文件及对应的图片文件
image_path = os.path.join(images_dir, filename.replace('.txt', '.jpg')) # 假设图片是.jpg格式
if os.path.isfile(image_path):
os.remove(image_path)
print(f'删除图片: {image_path}')
os.remove(file_path) # 删除标签文件
print(f'删除空标签文件: {file_path}')执行如上脚本后,就能保证图片与标签只会包含我们所需的索引1的类别了,然后修改下yaml为如下图
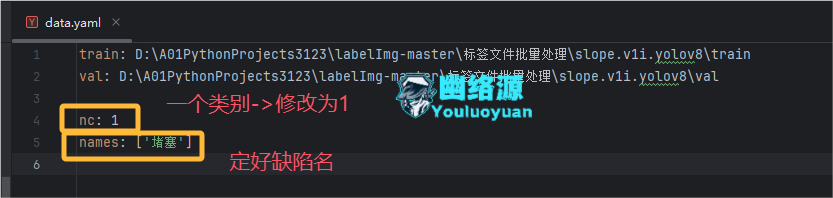
步骤4.处理剩下的类别的标签索引
上边将除了1之外的索引都去掉了,接下来继续将这些索引为1的标签批量更换为0,因为yaml中配置的类别默认是从索引0开始的,执行如下脚本,进行批量更换,别忘了将验证集也更换了
import os
def modify_txt_labels(folder_path,num):
for file_name in os.listdir(folder_path):
# 确保是 .txt 文件
if file_name.endswith('.txt'):
file_path = os.path.join(folder_path, file_name)
modified_lines = []
# 读取并修改每一行
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
parts = line.split() # 分割每行内容
if parts: # 如果这一行不是空行
parts[0] = num # 替换第一个数字为 num
modified_lines.append(' '.join(parts)) # 重新组合
# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:
file.write('\n'.join(modified_lines) + '\n')
#替换的数字
num='0'
# 替换为你的文件夹路径
folder_path = r"D:\A01PythonProjects3123\labelImg-master\标签文件批量处理\slope.v1i.yolov8\train\labels"
modify_txt_labels(folder_path,num)至此,我们从6大类的数据集中提取出了自己所需的一类数据集
以上是幽络源原创的使用Python脚本将yolo数据集提取部分特定类别的教程,如有不懂之处可加群询问交流






暂无评论内容