

前言
群内用户有需求,需要将笔趣阁的小说便捷的保存为文档到本地,幽络源站长初步了解笔趣阁,发现有反爬措施,小说内容为JS动态生成的,Python的requests库与requests_html已无法满足此需求,因此使用类似selenium但非selenium的无头浏览器爬虫针对笔趣阁实现小说爬取。
教程步骤
1.下载安装chromium
2.明确chromium默认安装路径
3.编写代码
4.明白爬取参数与注意事项
5.开始爬取
6.查看结果
步骤1.下载安装chromium
下载方式一:官网下载 -> Chromiun下载链接
下载方式二:夸克网盘下载保存 -> chromium下载器
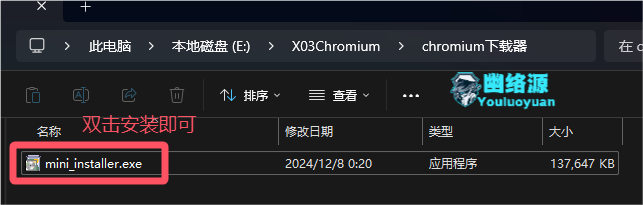
下载后,直接双击安装器完成安装即可,如图
步骤2.明确chromium默认安装路径
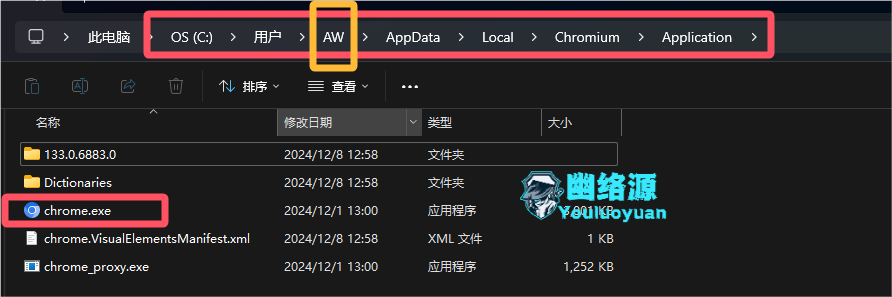
安装后,需要明白默认安装的位置,因为代码中会用到,我的电脑用户名为AW,因此被安装在了如下路径,如图
C:\Users\AW\AppData\Local\Chromium\Application\chrome.exe
步骤3.编写代码
这段代码中用到的库主要为pyppteer、python-docx,这两个库需额外下载
最终代码如下
import asyncio
import os
from docx import Document
from pyppeteer import launch
# 禁用自动下载 Chromium
os.environ["PYPPETEER_SKIP_CHROMIUM_DOWNLOAD"] = "true"
async def main():
# word名称
wordName = "宿命之环1~3章.docx"
# 笔趣阁域名
netName = "https://www.22biqu.com"
# 指定起始页的链接
firstPagePath = "/biqu5251/5259122.html"
# 指定结束页的链接,不要指定的太远,因为字数太多,打开word很卡的
endPagePath= "/biqu5251/5259124.html"
# 要爬取的链接
catchUrl = netName + firstPagePath
# 页数,可参考
pageCount=0
# 结束标志
endFlag=False
while True:
try:
#尝试打开一个word
doc = Document(wordName)
except:
doc = Document()
# 启动浏览器,指定手动下载的 Chromium 路径
browser = await launch(executablePath=r'C:\Users\AW\AppData\Local\Chromium\Application\chrome.exe', headless=True)
# 创建新页面
page = await browser.newPage()
# 打开目标页面
await page.goto(catchUrl)
# 使用 querySelector 获取 h1 标签且 class 为 title 的元素
element = await page.querySelector('h1.title')
if element:
# 获取该元素的文本内容
text = await page.evaluate('(element) => element.innerText', element)
doc.add_heading(text, level=1)
else:
print('Element not found.')
# 使用 querySelector 获取 id="content" 元素
content_element = await page.querySelector('#content')
if content_element:
# 获取 content 下所有 p 标签的内容
paragraphs = await content_element.querySelectorAll('p')
for paragraph in paragraphs:
# 获取每个 p 标签的文本内容并输出
text = await page.evaluate('(p) => p.innerText', paragraph)
doc.add_paragraph(text)
else:
print('Content element not found.')
# 使用 querySelector 获取 id="next_url" 的元素
element = await page.querySelector('#next_url')
next_url=""
if element:
# 获取该元素的 href 属性
next_url = await page.evaluate('(element) => element.getAttribute("href")', element)
# 拼接下一页爬取的链接
catchUrl=netName+next_url
else:
print('Element not found.')
# 关闭浏览器
await browser.close()
# 保存word
doc.save(wordName)
if endFlag:
break
pageCount+=1
print("已完成页码"+str(pageCount))
if next_url==endPagePath:
print("匹配到结束链接:"+str(endPagePath))
print("即将结束")
endFlag=True
# 运行异步主函数
asyncio.run(main())步骤4.明白爬取参数与注意事项
在使用上面的代码时,你需要明白函数中的一些参数需要你替换
wordName:也就是爬取后word保存的名称,我建议爬什么就取什么名,且加上多少章到多少章
netName:爬取网址的域名,这里固定不用改
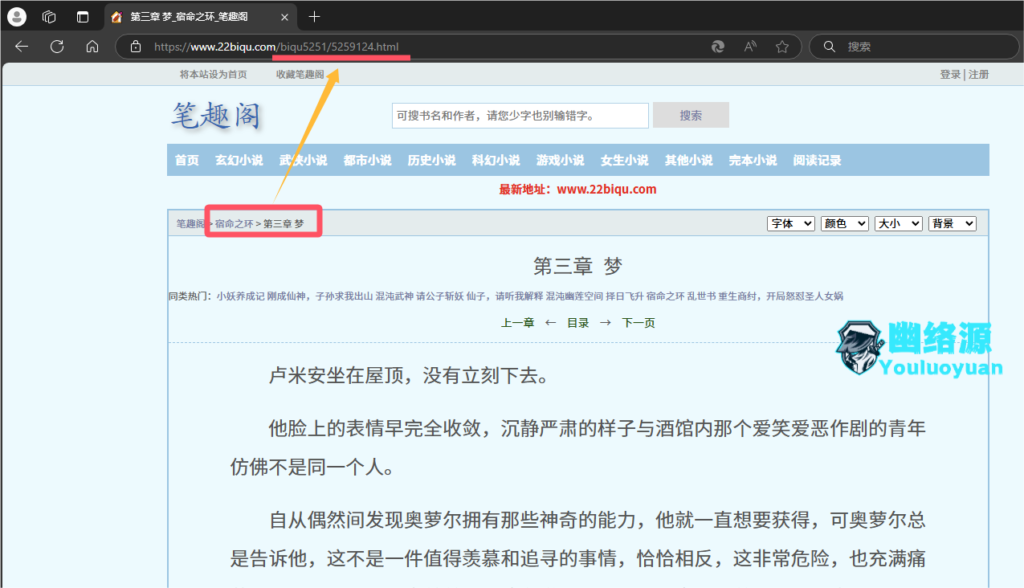
firstPathPath:这是起始页的路径,比如我要从《宿命之环》的第三开始爬起,则这里写为/biqu5251/5259124.html,看如下图你应该就明白了
endPagePath:和指定起始页一样,要在哪页结束,就把哪页的路径放进去,但是这里有个注意点
注意点:指定的结束页和起始页不要隔的太远了,因为word中字数太多,打开都卡,我测试了下,我爬取了200章到一个word中,结果是能打开,但是打开时比较卡,因此我建议分为几章节来爬取,不要妄图一次爬取所有章节,理论是可以的,但是你的电脑处理器肯定受不了
步骤5.开始爬取
我这里测试爬取笔趣阁-《宿命之环的1~5章》,因此我设置参数为如下
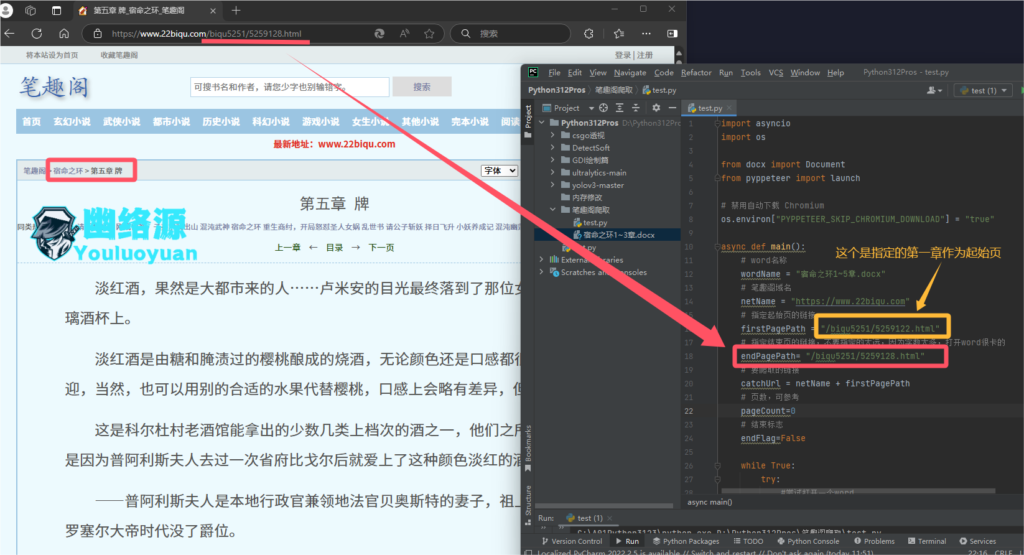
参数设置好后,直接运行代码即可,如图保存为了word
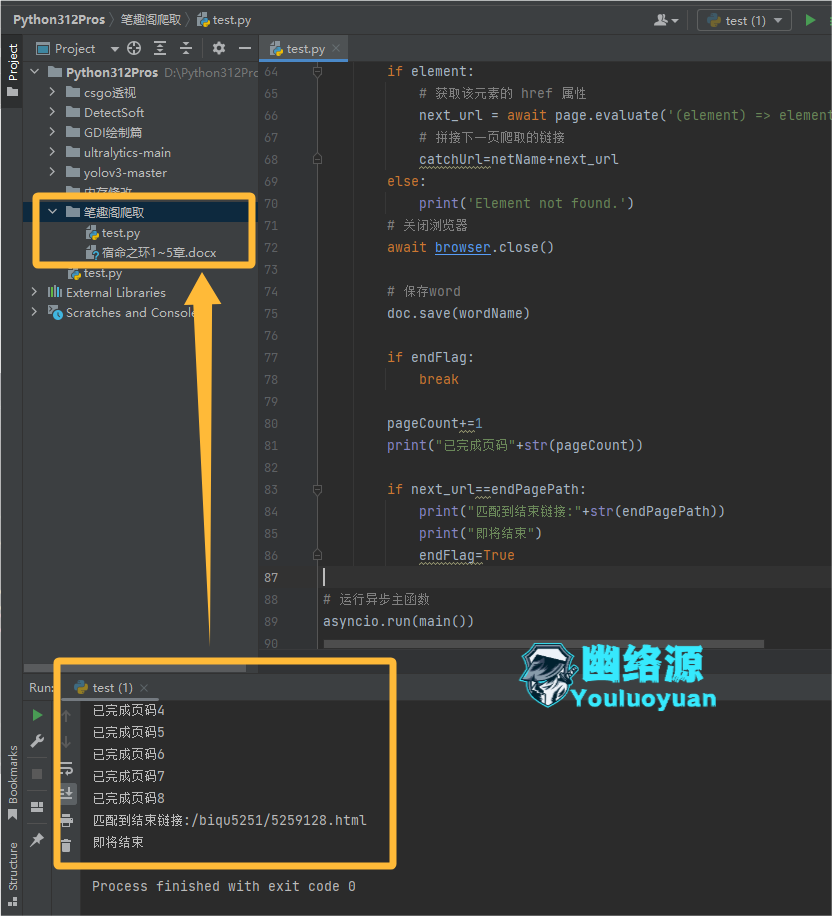
步骤6.查看结果
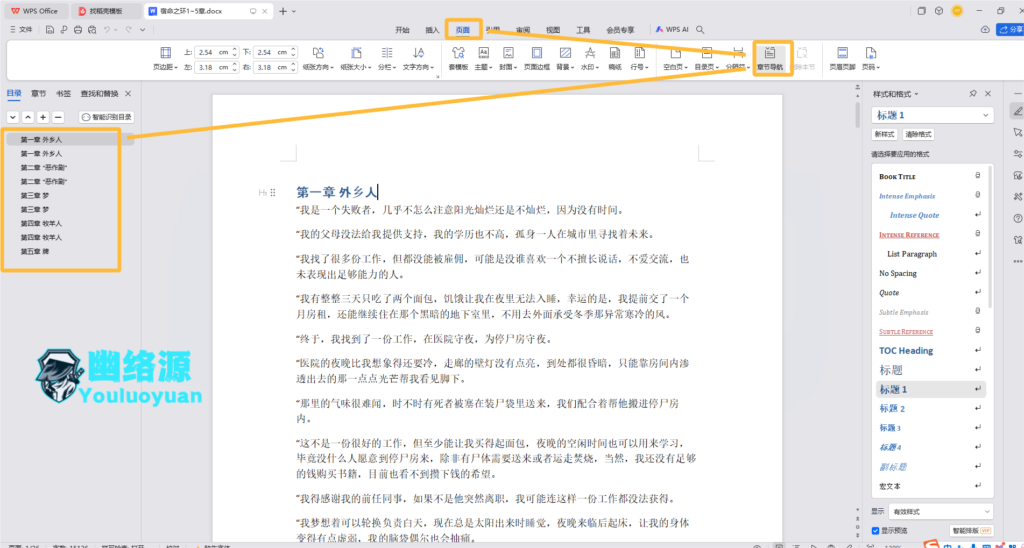
打开我们爬取的1~5章的word,如图,我这里做了将章节名作为标题,打开章节导航还可以点击标题直接定位到对应章节
结语
以上是幽络源的利用无头浏览器爬虫爬取笔趣阁小说的教程,对于此篇教程的内容,后续的优化我建议是做成一个PyQT程序,这样会更加方便。教程结束,如有不懂之处可加群询问,如有其他需求也可询问。







暂无评论内容